 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Kernel-Based View of Language Model Fine-Tuning
Paper and Code

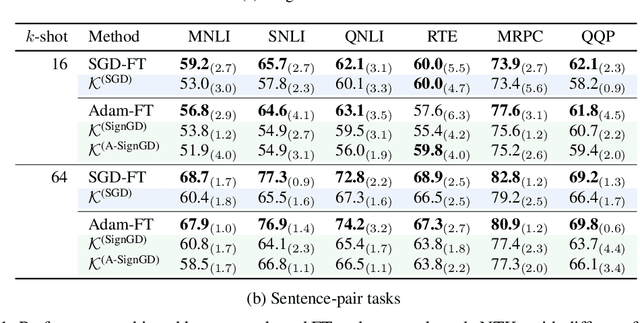


It has become standard to solve NLP tasks by fine-tuning pre-trained language models (LMs), especially in low-data settings. There is minimal theoretical understanding of empirical success, e.g., why fine-tuning a model with $10^8$ or more parameters on a couple dozen training points does not result in overfitting. We investigate whether the Neural Tangent Kernel (NTK) - which originated as a model to study the gradient descent dynamics of infinitely wide networks with suitable random initialization - describes fine-tuning of pre-trained LMs. This study was inspired by the decent performance of NTK for computer vision tasks (Wei et al., 2022). We also extend the NTK formalism to fine-tuning with Adam. We present extensive experiments that show that once the downstream task is formulated as a language modeling problem through prompting, the NTK lens can often reasonably describe the model updates during fine-tuning with both SGD and Adam. This kernel view also suggests an explanation for success of parameter-efficient subspace-based fine-tuning methods. Finally, we suggest a path toward a formal explanation for our findings via Tensor Programs (Yang, 2020).