 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA general sample complexity analysis of vanilla policy gradient
Paper and Code
Jul 23, 2021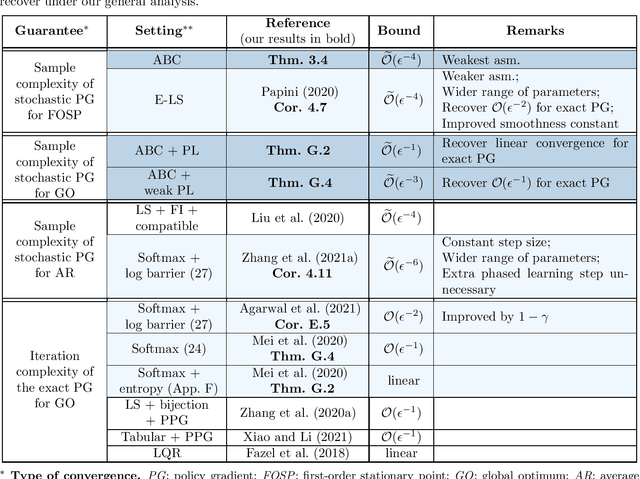
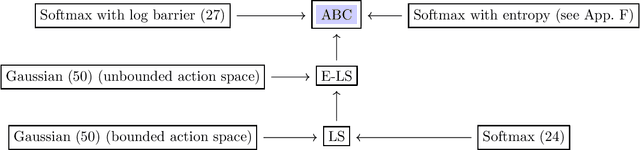

The policy gradient (PG) is one of the most popular methods for solving reinforcement learning (RL) problems. However, a solid theoretical understanding of even the "vanilla" PG has remained elusive for long time. In this paper, we apply recent tools developed for the analysis of SGD in non-convex optimization to obtain convergence guarantees for both REINFORCE and GPOMDP under smoothness assumption on the objective function and weak conditions on the second moment of the norm of the estimated gradient. When instantiated under common assumptions on the policy space, our general result immediately recovers existing $\widetilde{\mathcal{O}}(\epsilon^{-4})$ sample complexity guarantees, but for wider ranges of parameters (e.g., step size and batch size $m$) with respect to previous literature. Notably, our result includes the single trajectory case (i.e., $m=1$) and it provides a more accurate analysis of the dependency on problem-specific parameters by fixing previous results available in the literature. We believe that the integration of state-of-the-art tools from non-convex optimization may lead to identify a much broader range of problems where PG methods enjoy strong theoretical guarantees.