 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Game-Theoretic Perspective of Generalization in Reinforcement Learning
Paper and Code
Aug 07, 2022


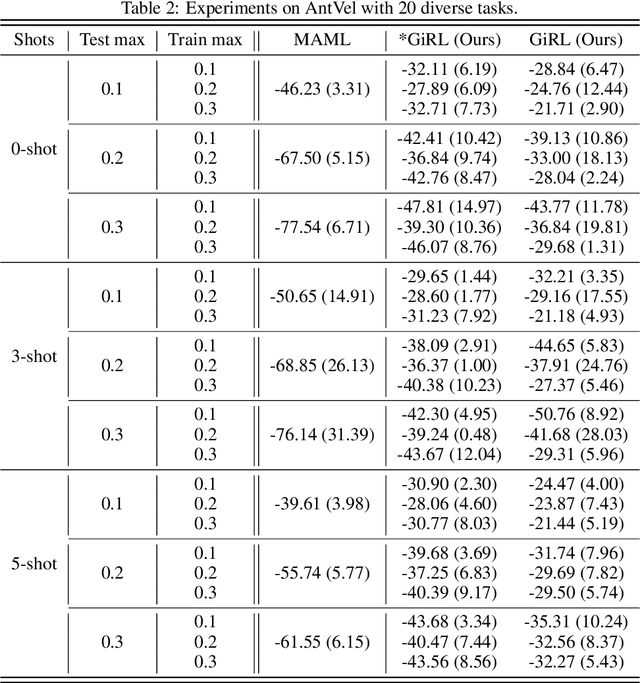
Generalization in reinforcement learning (RL) is of importance for real deployment of RL algorithms. Various schemes are proposed to address the generalization issues, including transfer learning, multi-task learning and meta learning, as well as the robust and adversarial reinforcement learning. However, there is not a unified formulation of the various schemes, as well as the comprehensive comparisons of methods across different schemes. In this work, we propose a game-theoretic framework for the generalization in reinforcement learning, named GiRL, where an RL agent is trained against an adversary over a set of tasks, where the adversary can manipulate the distributions over tasks within a given threshold. With different configurations, GiRL can reduce the various schemes mentioned above. To solve GiRL, we adapt the widely-used method in game theory, policy space response oracle (PSRO) with the following three important modifications: i) we use model-agnostic meta learning (MAML) as the best-response oracle, ii) we propose a modified projected replicated dynamics, i.e., R-PRD, which ensures the computed meta-strategy of the adversary fall in the threshold, and iii) we also propose a protocol for the few-shot learning of the multiple strategies during testing. Extensive experiments on MuJoCo environments demonstrate that our proposed methods can outperform existing baselines, e.g., MAML.