 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Fundamental Performance Limitation for Adversarial Classification
Paper and Code
Mar 15, 2019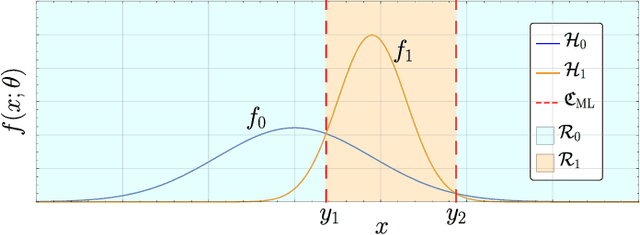



Despite the widespread use of machine learning algorithms to solve problems of technological, economic, and social relevance, provable guarantees on the performance of these data-driven algorithms are critically lacking, especially when the data originates from unreliable sources and is transmitted over unprotected and easily accessible channels. In this paper we take an important step to bridge this gap and formally show that, in a quest to optimize their accuracy, binary classification algorithms -- including those based on machine-learning techniques -- inevitably become more sensitive to adversarial manipulation of the data. Further, for a given class of algorithms with the same complexity (i.e., number of classification boundaries), the fundamental tradeoff curve between accuracy and sensitivity depends solely on the statistics of the data, and cannot be improved by tuning the algorithm.