 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Formally Robust Time Series Distance Metric
Paper and Code
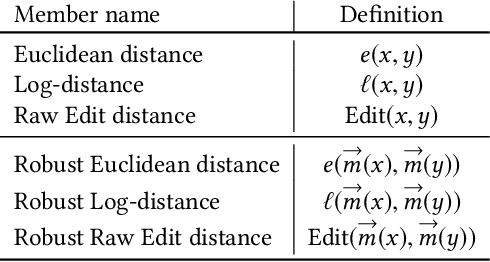
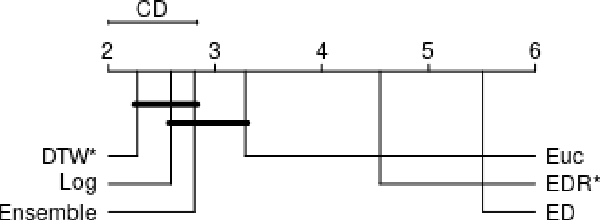
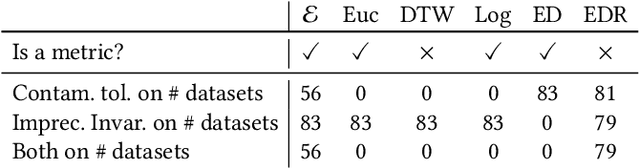
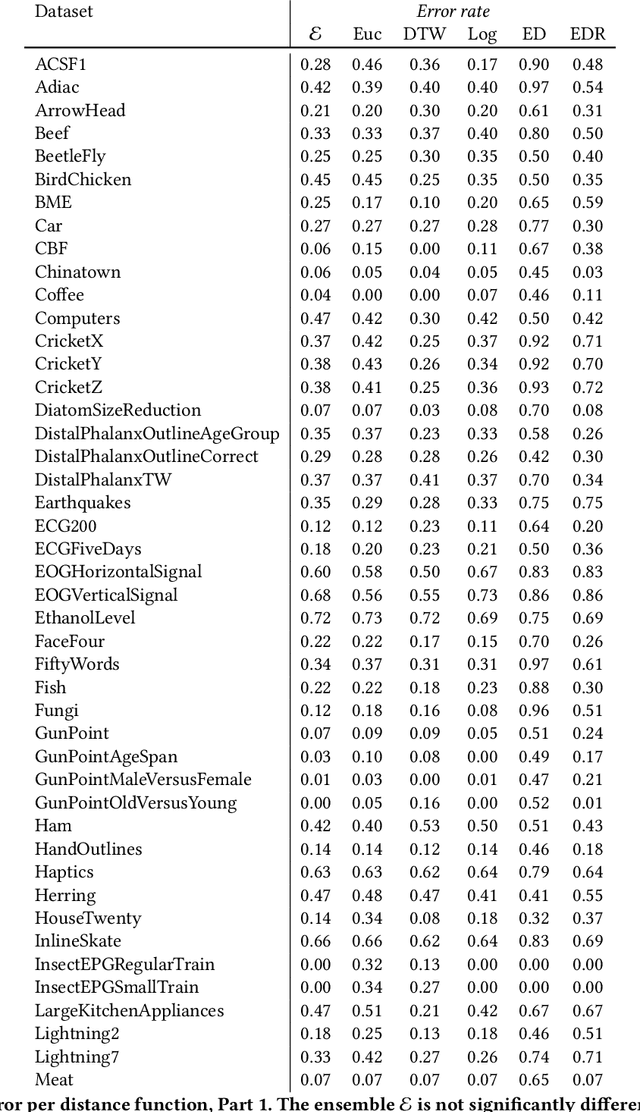
Distance-based classification is among the most competitive classification methods for time series data. The most critical component of distance-based classification is the selected distance function. Past research has proposed various different distance metrics or measures dedicated to particular aspects of real-world time series data, yet there is an important aspect that has not been considered so far: Robustness against arbitrary data contamination. In this work, we propose a novel distance metric that is robust against arbitrarily "bad" contamination and has a worst-case computational complexity of $\mathcal{O}(n\log n)$. We formally argue why our proposed metric is robust, and demonstrate in an empirical evaluation that the metric yields competitive classification accuracy when applied in k-Nearest Neighbor time series classification.