 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Feature Extraction based Model for Hate Speech Identification
Paper and Code


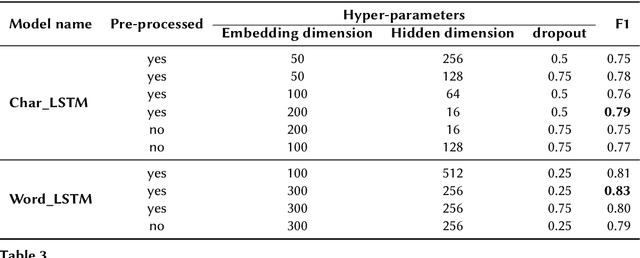

The detection of hate speech online has become an important task, as offensive language such as hurtful, obscene and insulting content can harm marginalized people or groups. This paper presents TU Berlin team experiments and results on the task 1A and 1B of the shared task on hate speech and offensive content identification in Indo-European languages 2021. The success of different Natural Language Processing models is evaluated for the respective subtasks throughout the competition. We tested different models based on recurrent neural networks in word and character levels and transfer learning approaches based on Bert on the provided dataset by the competition. Among the tested models that have been used for the experiments, the transfer learning-based models achieved the best results in both subtasks.