 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Dynamical View on Optimization Algorithms of Overparameterized Neural Networks
Paper and Code
Oct 25, 2020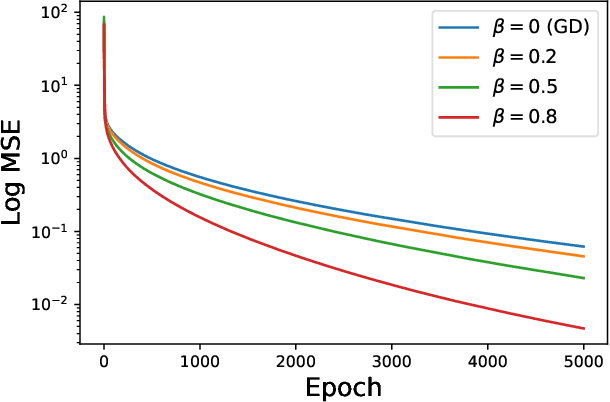
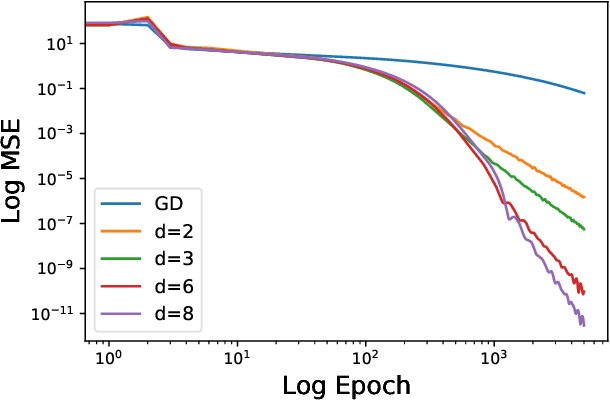
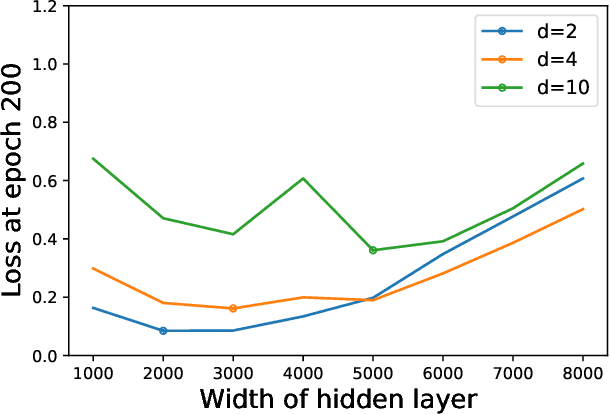
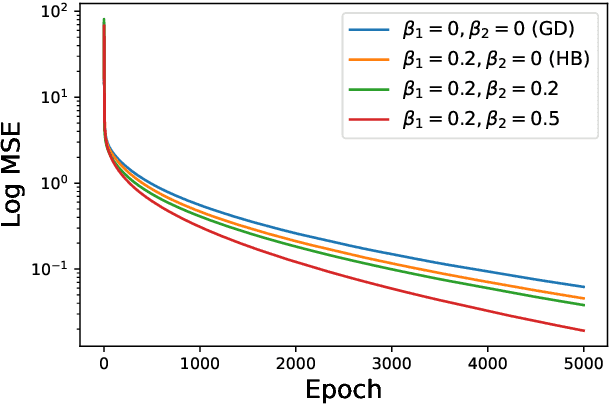
When equipped with efficient optimization algorithms, the over-parameterized neural networks have demonstrated high level of performance even though the loss function is non-convex and non-smooth. While many works have been focusing on understanding the loss dynamics by training neural networks with the gradient descent (GD), in this work, we consider a broad class of optimization algorithms that are commonly used in practice. For example, we show from a dynamical system perspective that the Heavy Ball (HB) method can converge to global minimum on mean squared error (MSE) at a linear rate (similar to GD); however, the Nesterov accelerated gradient descent (NAG) only converges to global minimum sublinearly. Our results rely on the connection between neural tangent kernel (NTK) and finite over-parameterized neural networks with ReLU activation, which leads to analyzing the limiting ordinary differential equations (ODE) for optimization algorithms. We show that, optimizing the non-convex loss over the weights corresponds to optimizing some strongly convex loss over the prediction error. As a consequence, we can leverage the classical convex optimization theory to understand the convergence behavior of neural networks. We believe our approach can also be extended to other loss functions and network architectures.