 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Divide-and-Conquer Approach towards Understanding Deep Networks
Paper and Code
Jul 14, 2019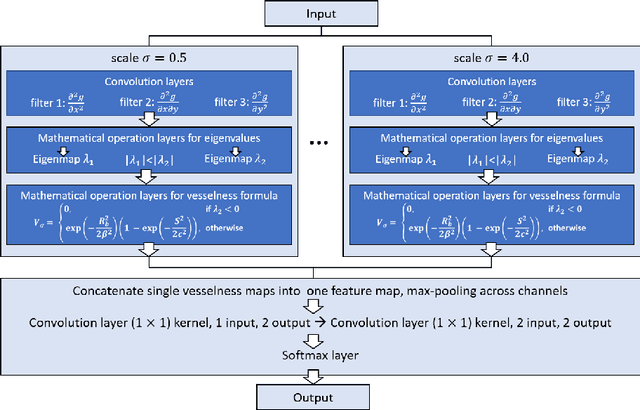
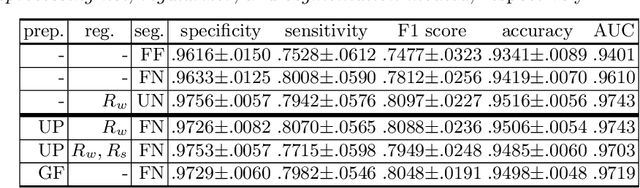
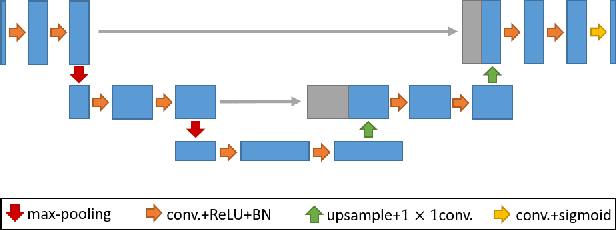
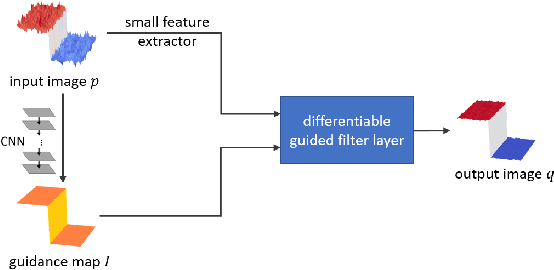
Deep neural networks have achieved tremendous success in various fields including medical image segmentation. However, they have long been criticized for being a black-box, in that interpretation, understanding and correcting architectures is difficult as there is no general theory for deep neural network design. Previously, precision learning was proposed to fuse deep architectures and traditional approaches. Deep networks constructed in this way benefit from the original known operator, have fewer parameters, and improved interpretability. However, they do not yield state-of-the-art performance in all applications. In this paper, we propose to analyze deep networks using known operators, by adopting a divide-and-conquer strategy to replace network components, whilst retaining its performance. The task of retinal vessel segmentation is investigated for this purpose. We start with a high-performance U-Net and show by step-by-step conversion that we are able to divide the network into modules of known operators. The results indicate that a combination of a trainable guided filter and a trainable version of the Frangi filter yields a performance at the level of U-Net (AUC 0.974 vs. 0.972) with a tremendous reduction in parameters (111,536 vs. 9,575). In addition, the trained layers can be mapped back into their original algorithmic interpretation and analyzed using standard tools of signal processing.