 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Dimensionality Reduction Method for Finding Least Favorable Priors with a Focus on Bregman Divergence
Paper and Code
Feb 23, 2022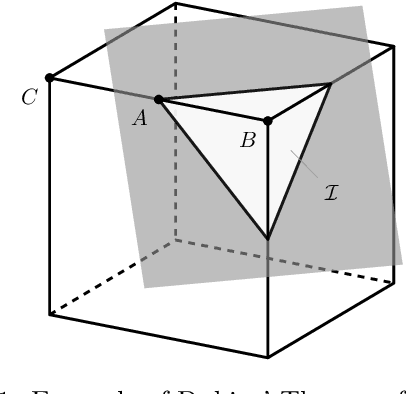
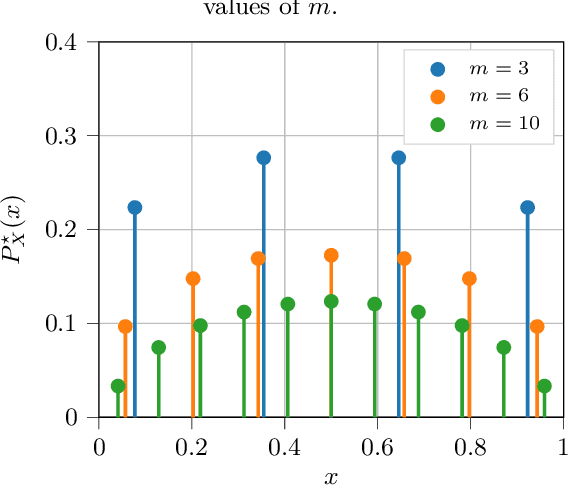
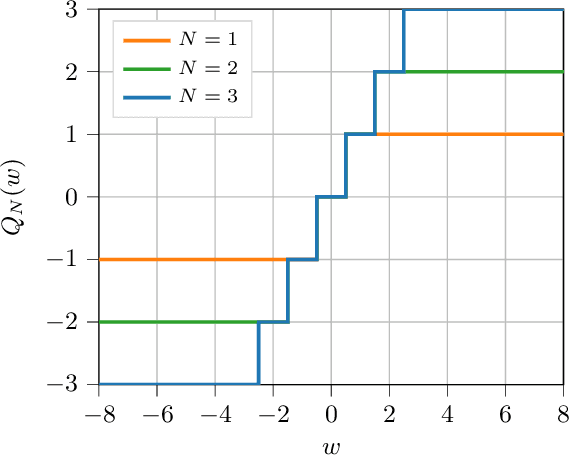
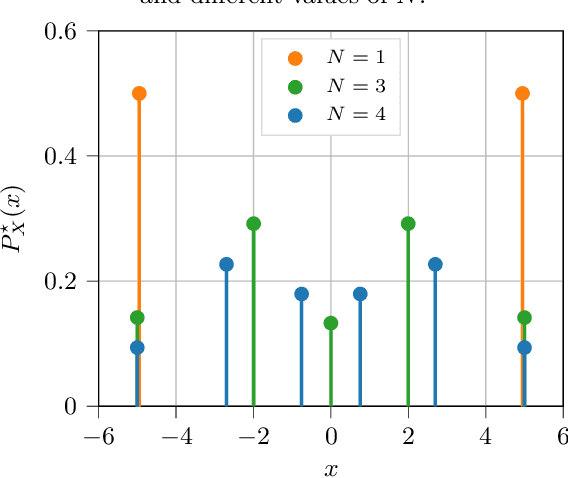
A common way of characterizing minimax estimators in point estimation is by moving the problem into the Bayesian estimation domain and finding a least favorable prior distribution. The Bayesian estimator induced by a least favorable prior, under mild conditions, is then known to be minimax. However, finding least favorable distributions can be challenging due to inherent optimization over the space of probability distributions, which is infinite-dimensional. This paper develops a dimensionality reduction method that allows us to move the optimization to a finite-dimensional setting with an explicit bound on the dimension. The benefit of this dimensionality reduction is that it permits the use of popular algorithms such as projected gradient ascent to find least favorable priors. Throughout the paper, in order to make progress on the problem, we restrict ourselves to Bayesian risks induced by a relatively large class of loss functions, namely Bregman divergences.