 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA determinantal point process for column subset selection
Paper and Code



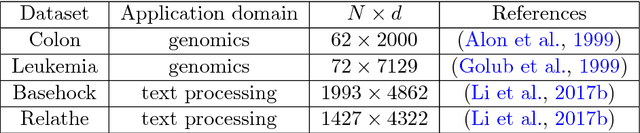
Dimensionality reduction is a first step of many machine learning pipelines. Two popular approaches are principal component analysis, which projects onto a small number of well chosen but non-interpretable directions, and feature selection, which selects a small number of the original features. Feature selection can be abstracted as a numerical linear algebra problem called the column subset selection problem (CSSP). CSSP corresponds to selecting the best subset of columns of a matrix $X \in \mathbb{R}^{N \times d}$, where \emph{best} is often meant in the sense of minimizing the approximation error, i.e., the norm of the residual after projection of $X$ onto the space spanned by the selected columns. Such an optimization over subsets of $\{1,\dots,d\}$ is usually impractical. One workaround that has been vastly explored is to resort to polynomial-cost, random subset selection algorithms that favor small values of this approximation error. We propose such a randomized algorithm, based on sampling from a projection determinantal point process (DPP), a repulsive distribution over a fixed number $k$ of indices $\{1,\dots,d\}$ that favors diversity among the selected columns. We give bounds on the ratio of the expected approximation error for this DPP over the optimal error of PCA. These bounds improve over the state-of-the-art bounds of \emph{volume sampling} when some realistic structural assumptions are satisfied for $X$. Numerical experiments suggest that our bounds are tight, and that our algorithms have comparable performance with the \emph{double phase} algorithm, often considered to be the practical state-of-the-art. Column subset selection with DPPs thus inherits the best of both worlds: good empirical performance and tight error bounds.