 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Deep Reinforcement Learning Approach for Finding Non-Exploitable Strategies in Two-Player Atari Games
Paper and Code
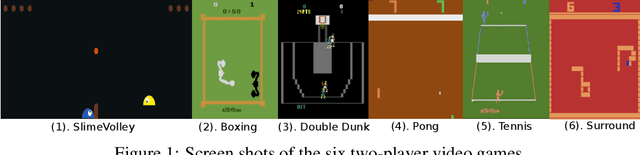

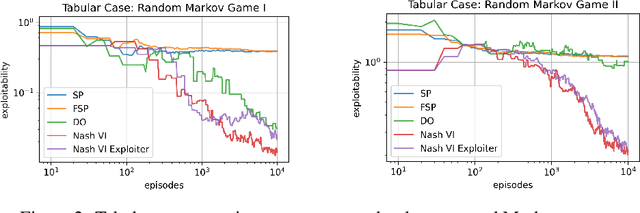
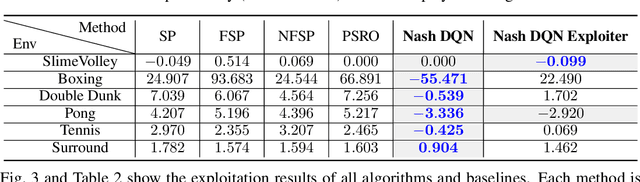
This paper proposes novel, end-to-end deep reinforcement learning algorithms for learning two-player zero-sum Markov games. Our objective is to find the Nash Equilibrium policies, which are free from exploitation by adversarial opponents. Distinct from prior efforts on finding Nash equilibria in extensive-form games such as Poker, which feature tree-structured transition dynamics and discrete state space, this paper focuses on Markov games with general transition dynamics and continuous state space. We propose (1) Nash DQN algorithm, which integrates DQN with a Nash finding subroutine for the joint value functions; and (2) Nash DQN Exploiter algorithm, which additionally adopts an exploiter for guiding agent's exploration. Our algorithms are the practical variants of theoretical algorithms which are guaranteed to converge to Nash equilibria in the basic tabular setting. Experimental evaluation on both tabular examples and two-player Atari games demonstrates the robustness of the proposed algorithms against adversarial opponents, as well as their advantageous performance over existing methods.