 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Cycle-GAN Approach to Model Natural Perturbations in Speech for ASR Applications
Paper and Code
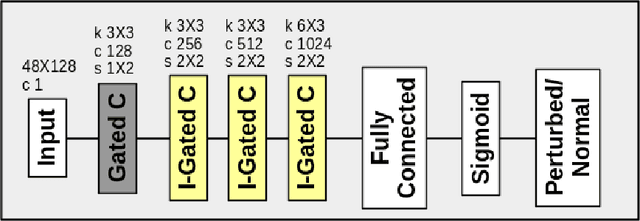

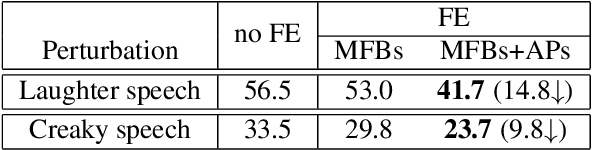
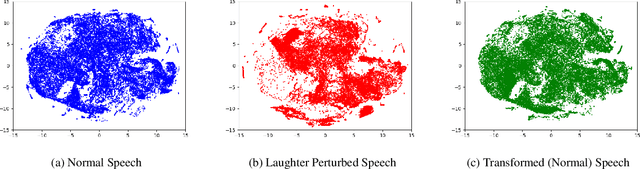
Naturally introduced perturbations in audio signal, caused by emotional and physical states of the speaker, can significantly degrade the performance of Automatic Speech Recognition (ASR) systems. In this paper, we propose a front-end based on Cycle-Consistent Generative Adversarial Network (CycleGAN) which transforms naturally perturbed speech into normal speech, and hence improves the robustness of an ASR system. The CycleGAN model is trained on non-parallel examples of perturbed and normal speech. Experiments on spontaneous laughter-speech and creaky-speech datasets show that the performance of four different ASR systems improve by using speech obtained from CycleGAN based front-end, as compared to directly using the original perturbed speech. Visualization of the features of the laughter perturbed speech and those generated by the proposed front-end further demonstrates the effectiveness of our approach.