 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Curriculum Domain Adaptation Approach to the Semantic Segmentation of Urban Scenes
Paper and Code



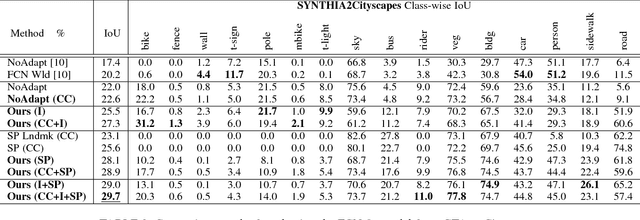
During the last half decade, convolutional neural networks (CNNs) have triumphed over semantic segmentation, which is one of the core tasks in many applications such as autonomous driving and augmented reality. However, to train CNNs requires a considerable amount of data, which is difficult to collect and laborious to annotate. Recent advances in computer graphics make it possible to train CNNs on photo-realistic synthetic imagery with computer-generated annotations. Despite this, the domain mismatch between the real images and the synthetic data hinders the models' performance. Hence, we propose a curriculum-style learning approach to minimizing the domain gap in urban scene semantic segmentation. The curriculum domain adaptation solves easy tasks first to infer necessary properties about the target domain; in particular, the first task is to learn global label distributions over images and local distributions over landmark superpixels. These are easy to estimate because images of urban scenes have strong idiosyncrasies (e.g., the size and spatial relations of buildings, streets, cars, etc.). We then train a segmentation network, while regularizing its predictions in the target domain to follow those inferred properties. In experiments, our method outperforms the baselines on two datasets and two backbone networks. We also report extensive ablation studies about our approach.