 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Constant Approximation Algorithm for Sequential No-Substitution k-Median Clustering under a Random Arrival Order
Paper and Code
Feb 08, 2021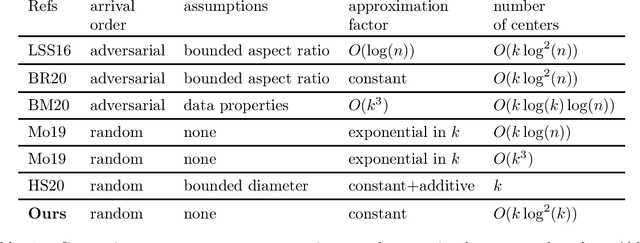

We study k-median clustering under the sequential no-substitution setting. In this setting, a data stream is sequentially observed, and some of the points are selected by the algorithm as cluster centers. However, a point can be selected as a center only immediately after it is observed, before observing the next point. In addition, a selected center cannot be substituted later. We give a new algorithm for this setting that obtains a constant approximation factor on the optimal risk under a random arrival order. This is the first such algorithm that holds without any assumptions on the input data and selects a non-trivial number of centers. The number of selected centers is quasi-linear in k. Our algorithm and analysis are based on a careful risk estimation that avoids outliers, a new concept of a linear bin division, and repeated calculations using an offline clustering algorithm.