 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Study of Deep Bidirectional LSTM RNNs for Acoustic Modeling in Speech Recognition
Paper and Code
Mar 29, 2017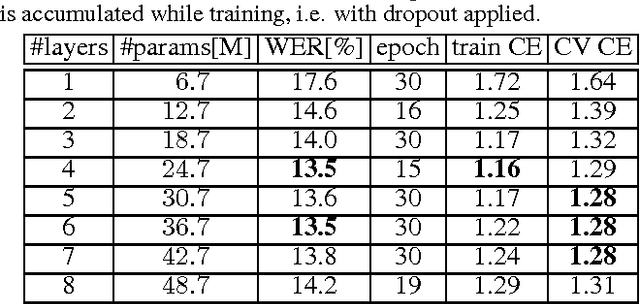
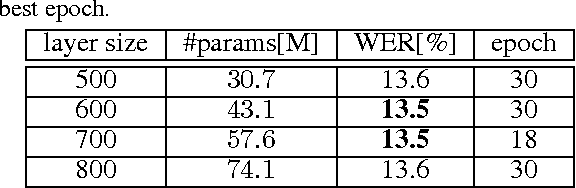
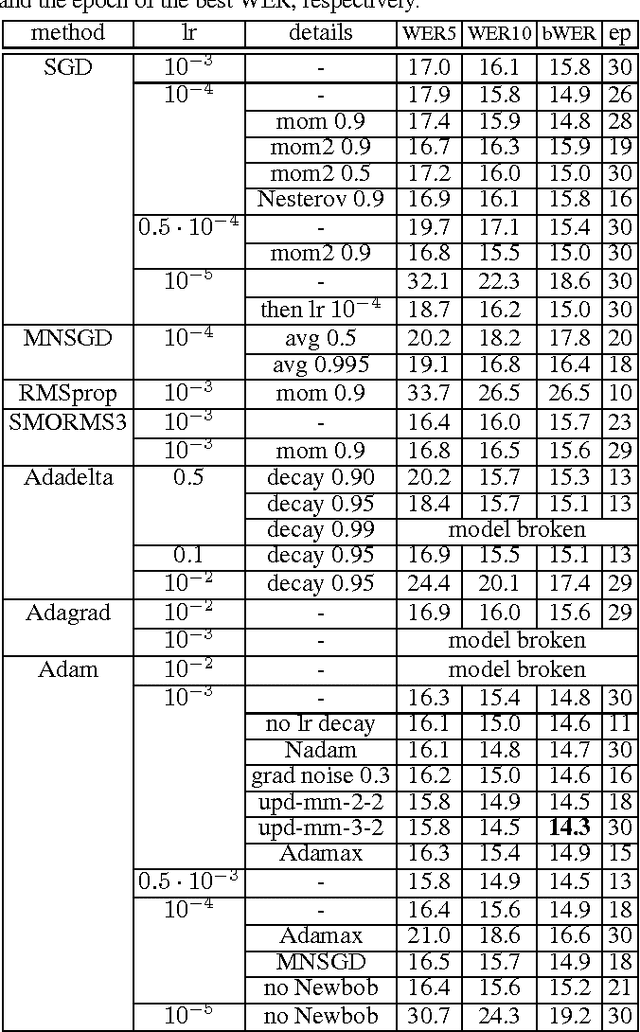
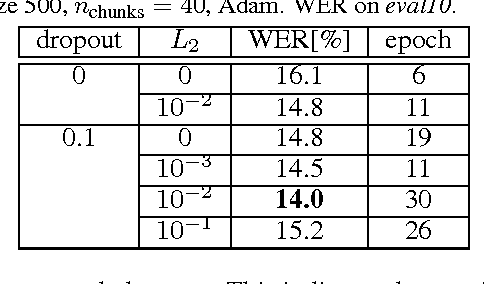
We present a comprehensive study of deep bidirectional long short-term memory (LSTM) recurrent neural network (RNN) based acoustic models for automatic speech recognition (ASR). We study the effect of size and depth and train models of up to 8 layers. We investigate the training aspect and study different variants of optimization methods, batching, truncated backpropagation, different regularization techniques such as dropout and $L_2$ regularization, and different gradient clipping variants. The major part of the experimental analysis was performed on the Quaero corpus. Additional experiments also were performed on the Switchboard corpus. Our best LSTM model has a relative improvement in word error rate of over 14\% compared to our best feed-forward neural network (FFNN) baseline on the Quaero task. On this task, we get our best result with an 8 layer bidirectional LSTM and we show that a pretraining scheme with layer-wise construction helps for deep LSTMs. Finally we compare the training calculation time of many of the presented experiments in relation with recognition performance. All the experiments were done with RETURNN, the RWTH extensible training framework for universal recurrent neural networks in combination with RASR, the RWTH ASR toolkit.