 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Competitive Edge: Can FPGAs Beat GPUs at DCNN Inference Acceleration in Resource-Limited Edge Computing Applications?
Paper and Code
Jan 30, 2021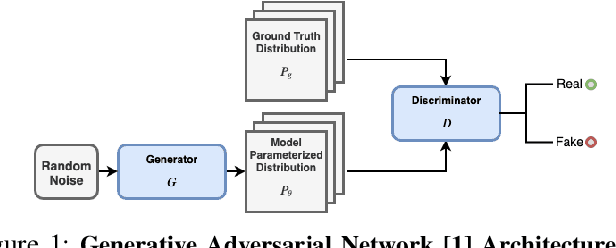

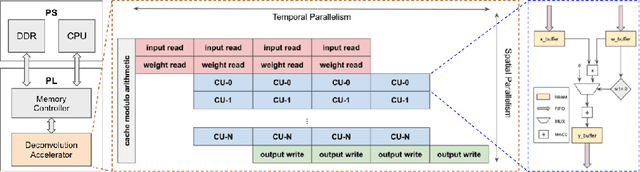
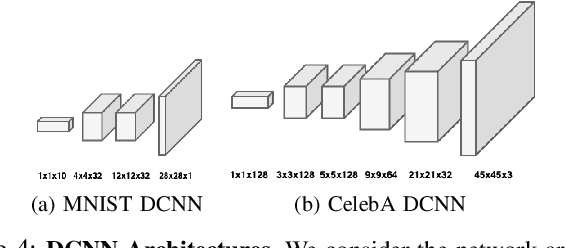
When trained as generative models, Deep Learning algorithms have shown exceptional performance on tasks involving high dimensional data such as image denoising and super-resolution. In an increasingly connected world dominated by mobile and edge devices, there is surging demand for these algorithms to run locally on embedded platforms. FPGAs, by virtue of their reprogrammability and low-power characteristics, are ideal candidates for these edge computing applications. As such, we design a spatio-temporally parallelized hardware architecture capable of accelerating a deconvolution algorithm optimized for power-efficient inference on a resource-limited FPGA. We propose this FPGA-based accelerator to be used for Deconvolutional Neural Network (DCNN) inference in low-power edge computing applications. To this end, we develop methods that systematically exploit micro-architectural innovations, design space exploration, and statistical analysis. Using a Xilinx PYNQ-Z2 FPGA, we leverage our architecture to accelerate inference for two DCNNs trained on the MNIST and CelebA datasets using the Wasserstein GAN framework. On these networks, our FPGA design achieves a higher throughput to power ratio with lower run-to-run variation when compared to the NVIDIA Jetson TX1 edge computing GPU.