 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Closer Look at Linguistic Knowledge in Masked Language Models: The Case of Relative Clauses in American English
Paper and Code


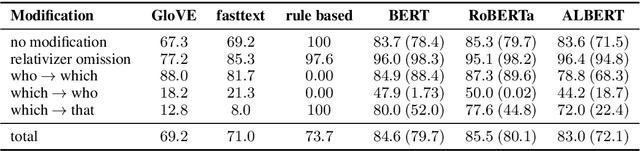

Transformer-based language models achieve high performance on various tasks, but we still lack understanding of the kind of linguistic knowledge they learn and rely on. We evaluate three models (BERT, RoBERTa, and ALBERT), testing their grammatical and semantic knowledge by sentence-level probing, diagnostic cases, and masked prediction tasks. We focus on relative clauses (in American English) as a complex phenomenon needing contextual information and antecedent identification to be resolved. Based on a naturalistic dataset, probing shows that all three models indeed capture linguistic knowledge about grammaticality, achieving high performance. Evaluation on diagnostic cases and masked prediction tasks considering fine-grained linguistic knowledge, however, shows pronounced model-specific weaknesses especially on semantic knowledge, strongly impacting models' performance. Our results highlight the importance of (a)model comparison in evaluation task and (b) building up claims of model performance and the linguistic knowledge they capture beyond purely probing-based evaluations.