 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA classification for the performance of online SGD for high-dimensional inference
Paper and Code
Apr 22, 2020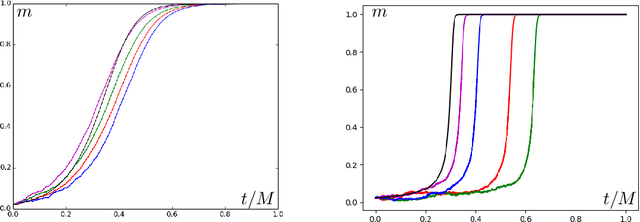
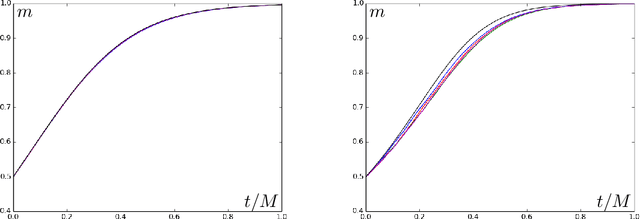
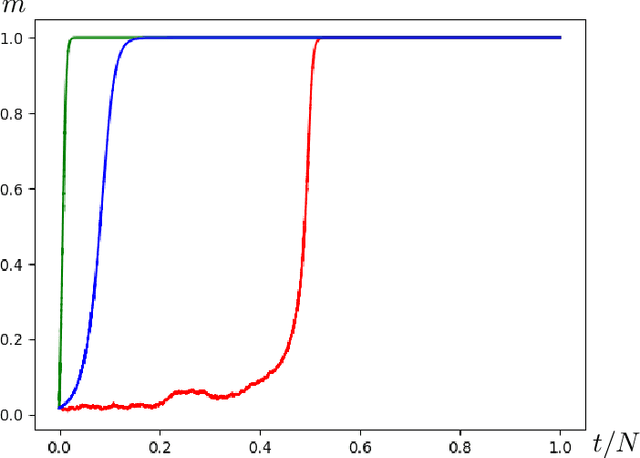
Stochastic gradient descent (SGD) is a popular algorithm for optimization problems arising in high-dimensional inference tasks. Here one produces an estimator of an unknown parameter from a large number of independent samples of data by iteratively optimizing a loss function. This loss function is high-dimensional, random, and often complex. We study here the performance of the simplest version of SGD, namely online SGD, in the initial "search" phase, where the algorithm is far from a trust region and the loss landscape is highly non-convex. To this end, we investigate the performance of online SGD at attaining a "better than random" correlation with the unknown parameter, i.e, achieving weak recovery. Our contribution is a classification of the difficulty of typical instances of this task for online SGD in terms of the number of samples required as the dimension diverges. This classification depends only on an intrinsic property of the population loss, which we call the information exponent. Using the information exponent, we find that there are three distinct regimes---the easy, critical, and difficult regimes---where one requires linear, quasilinear, and polynomially many samples (in the dimension) respectively to achieve weak recovery. We illustrate our approach by applying it to a wide variety of estimation tasks such as parameter estimation for generalized linear models, two-component Gaussian mixture models, phase retrieval, and spiked matrix and tensor models, as well as supervised learning for single-layer networks with general activation functions. In this latter case, our results translate into a classification of the difficulty of this task in terms of the Hermite decomposition of the activation function.