Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Cantor-Kantorovich Metric Between Markov Decision Processes with Application to Transfer Learning
Paper and Code
Jul 11, 2024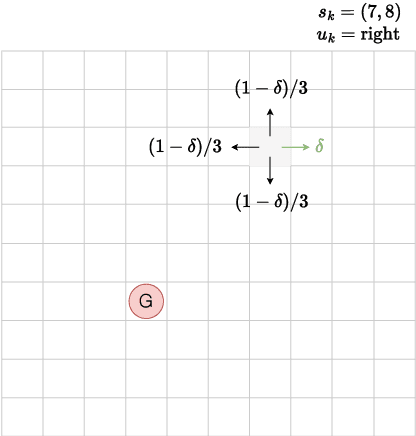
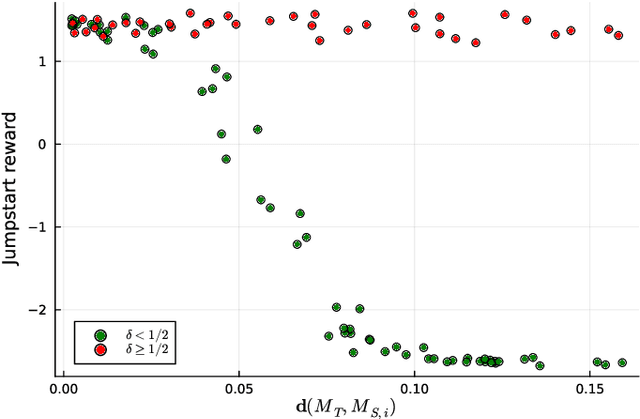
We extend the notion of Cantor-Kantorovich distance between Markov chains introduced by (Banse et al., 2023) in the context of Markov Decision Processes (MDPs). The proposed metric is well-defined and can be efficiently approximated given a finite horizon. Then, we provide numerical evidences that the latter metric can lead to interesting applications in the field of reinforcement learning. In particular, we show that it could be used for forecasting the performance of transfer learning algorithms.
* Presented at the 26th International Symposium on Mathematical Theory
of Networks and Systems (Cambridge, UK)
View paper on