 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Shape Knowledge Graph for Cross-domain and Cross-modal 3D Shape Retrieval
Paper and Code
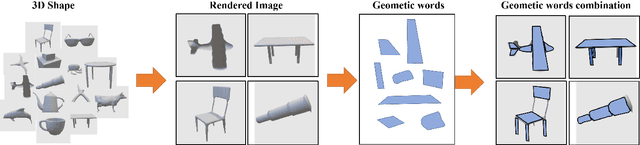

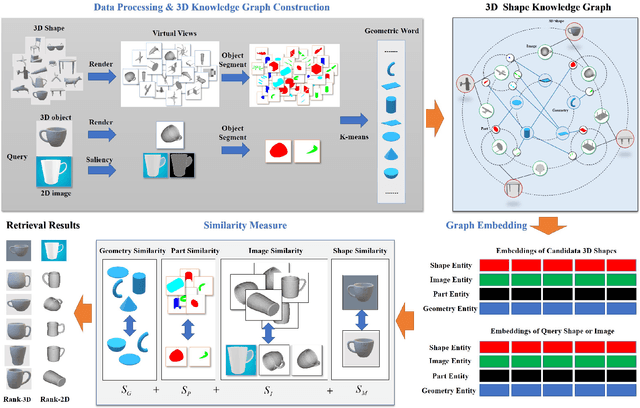

With the development of 3D modeling and fabrication, 3D shape retrieval has become a hot topic. In recent years, several strategies have been put forth to address this retrieval issue. However, it is difficult for them to handle cross-modal 3D shape retrieval because of the natural differences between modalities. In this paper, we propose an innovative concept, namely, geometric words, which is regarded as the basic element to represent any 3D or 2D entity by combination, and assisted by which, we can simultaneously handle cross-domain or cross-modal retrieval problems. First, to construct the knowledge graph, we utilize the geometric word as the node, and then use the category of the 3D shape as well as the attribute of the geometry to bridge the nodes. Second, based on the knowledge graph, we provide a unique way for learning each entity's embedding. Finally, we propose an effective similarity measure to handle the cross-domain and cross-modal 3D shape retrieval. Specifically, every 3D or 2D entity could locate its geometric terms in the 3D knowledge graph, which serve as a link between cross-domain and cross-modal data. Thus, our approach can achieve the cross-domain and cross-modal 3D shape retrieval at the same time. We evaluated our proposed method on the ModelNet40 dataset and ShapeNetCore55 dataset for both the 3D shape retrieval task and cross-domain 3D shape retrieval task. The classic cross-modal dataset (MI3DOR) is utilized to evaluate cross-modal 3D shape retrieval. Experimental results and comparisons with state-of-the-art methods illustrate the superiority of our approach.