 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Neighborhood Convolution: Learning Depth-Aware Features for RGB-D and RGB Semantic Segmentation
Paper and Code
Oct 03, 2019
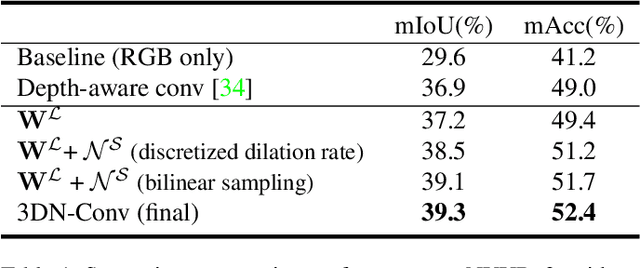


A key challenge for RGB-D segmentation is how to effectively incorporate 3D geometric information from the depth channel into 2D appearance features. We propose to model the effective receptive field of 2D convolution based on the scale and locality from the 3D neighborhood. Standard convolutions are local in the image space ($u, v$), often with a fixed receptive field of 3x3 pixels. We propose to define convolutions local with respect to the corresponding point in the 3D real-world space ($x, y, z$), where the depth channel is used to adapt the receptive field of the convolution, which yields the resulting filters invariant to scale and focusing on the certain range of depth. We introduce 3D Neighborhood Convolution (3DN-Conv), a convolutional operator around 3D neighborhoods. Further, we can use estimated depth to use our RGB-D based semantic segmentation model from RGB input. Experimental results validate that our proposed 3DN-Conv operator improves semantic segmentation, using either ground-truth depth (RGB-D) or estimated depth (RGB).