 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge1st Place Solution for YouTubeVOS Challenge 2022: Referring Video Object Segmentation
Paper and Code
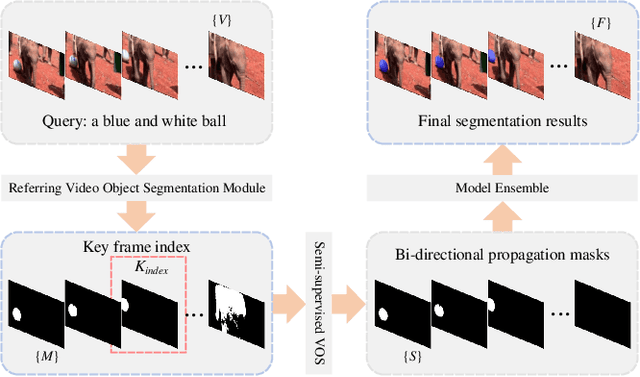


The task of referring video object segmentation aims to segment the object in the frames of a given video to which the referring expressions refer. Previous methods adopt multi-stage approach and design complex pipelines to obtain promising results. Recently, the end-to-end method based on Transformer has proved its superiority. In this work, we draw on the advantages of the above methods to provide a simple and effective pipeline for RVOS. Firstly, We improve the state-of-the-art one-stage method ReferFormer to obtain mask sequences that are strongly correlated with language descriptions. Secondly, based on a reliable and high-quality keyframe, we leverage the superior performance of video object segmentation model to further enhance the quality and temporal consistency of the mask results. Our single model reaches 70.3 J &F on the Referring Youtube-VOS validation set and 63.0 on the test set. After ensemble, we achieve 64.1 on the final leaderboard, ranking 1st place on CVPR2022 Referring Youtube-VOS challenge. Code will be available at https://github.com/Zhiweihhh/cvpr2022-rvos-challenge.git.