 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSource Inference Attacks in Federated Learning
Sep 13, 2021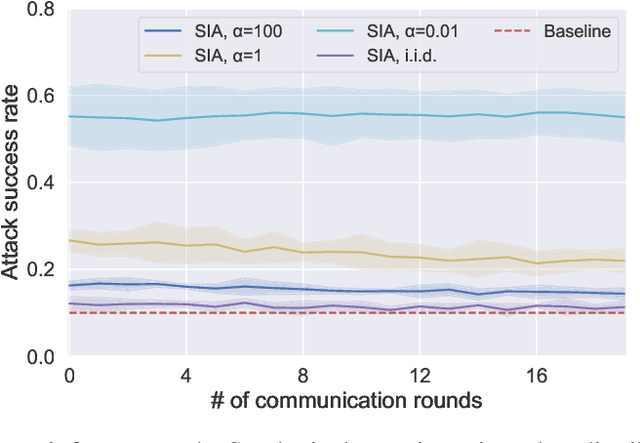

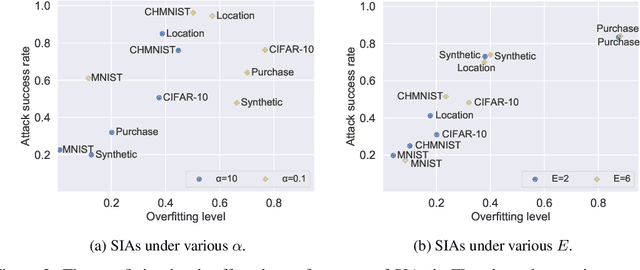
Federated learning (FL) has emerged as a promising privacy-aware paradigm that allows multiple clients to jointly train a model without sharing their private data. Recently, many studies have shown that FL is vulnerable to membership inference attacks (MIAs) that can distinguish the training members of the given model from the non-members. However, existing MIAs ignore the source of a training member, i.e., the information of which client owns the training member, while it is essential to explore source privacy in FL beyond membership privacy of examples from all clients. The leakage of source information can lead to severe privacy issues. For example, identification of the hospital contributing to the training of an FL model for COVID-19 pandemic can render the owner of a data record from this hospital more prone to discrimination if the hospital is in a high risk region. In this paper, we propose a new inference attack called source inference attack (SIA), which can derive an optimal estimation of the source of a training member. Specifically, we innovatively adopt the Bayesian perspective to demonstrate that an honest-but-curious server can launch an SIA to steal non-trivial source information of the training members without violating the FL protocol. The server leverages the prediction loss of local models on the training members to achieve the attack effectively and non-intrusively. We conduct extensive experiments on one synthetic and five real datasets to evaluate the key factors in an SIA, and the results show the efficacy of the proposed source inference attack.
Membership Inference Attacks on Machine Learning: A Survey
Mar 17, 2021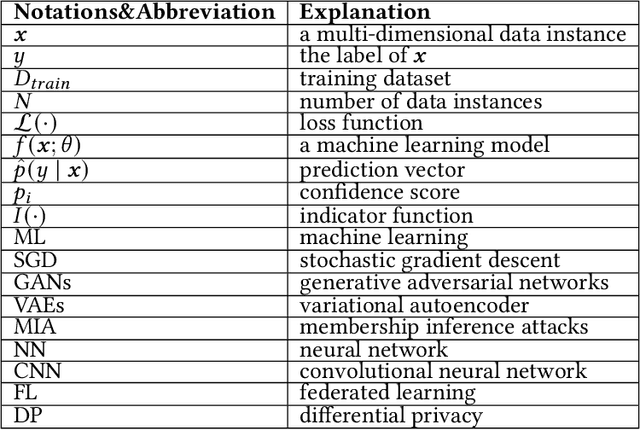
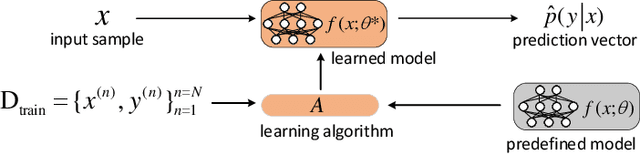

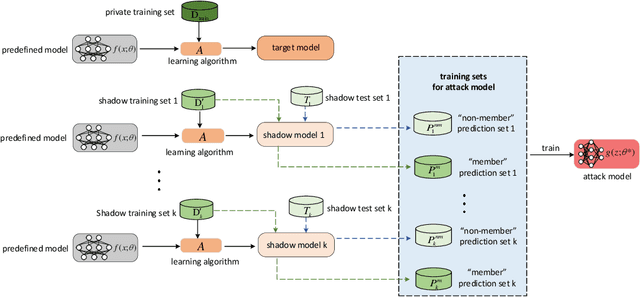
Membership inference attack aims to identify whether a data sample was used to train a machine learning model or not. It can raise severe privacy risks as the membership can reveal an individual's sensitive information. For example, identifying an individual's participation in a hospital's health analytics training set reveals that this individual was once a patient in that hospital. Membership inference attacks have been shown to be effective on various machine learning models, such as classification models, generative models, and sequence-to-sequence models. Meanwhile, many methods are proposed to defend such a privacy attack. Although membership inference attack is an emerging and rapidly growing research area, there is no comprehensive survey on this topic yet. In this paper, we bridge this important gap in membership inference attack literature. We present the first comprehensive survey of membership inference attacks. We summarize and categorize existing membership inference attacks and defenses and explicitly present how to implement attacks in various settings. Besides, we discuss why membership inference attacks work and summarize the benchmark datasets to facilitate comparison and ensure fairness of future work. Finally, we propose several possible directions for future research and possible applications relying on reviewed works.