 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnergy-Based Open-Set Active Learning for Object Classification
Apr 22, 2026Active learning (AL) has emerged as a crucial methodology for minimizing labeling costs in deep learning by selecting the most valuable samples from a pool of unlabeled data for annotation. Traditional AL operates under a closed-set assumption, where all classes in the dataset are known and consistent. However, real-world scenarios often present open-set conditions in which unlabeled data contains both known and unknown classes. In such environments, standard AL techniques struggle. They can mistakenly query samples from unknown categories, leading to inefficient use of annotation budgets. In this paper, we propose a novel dual-stage energy-based framework for open-set AL. Our method employs two specialized energy-based models (EBMs). The first, an energy-based known/unknown separator, filters out samples likely to belong to unknown classes. The second, an energy-based sample scorer, assesses the informativeness of the filtered known samples. Using the energy landscape, our models distinguish between data points from known and unknown classes in the unlabeled pool by assigning lower energy to known samples and higher energy to unknown samples, ensuring that only samples from classes of interest are selected for labeling. By integrating these components, our approach ensures efficient and targeted sample selection, maximizing learning impact in each iteration. Experiments on 2D (CIFAR-10, CIFAR-100, TinyImageNet) and 3D (ModelNet40) object classification benchmarks demonstrates that our framework outperforms existing approaches, achieving superior annotation efficiency and classification performance in open-set environments.
Semi-Supervised Variational Adversarial Active Learning via Learning to Rank and Agreement-Based Pseudo Labeling
Aug 23, 2024



Active learning aims to alleviate the amount of labor involved in data labeling by automating the selection of unlabeled samples via an acquisition function. For example, variational adversarial active learning (VAAL) leverages an adversarial network to discriminate unlabeled samples from labeled ones using latent space information. However, VAAL has the following shortcomings: (i) it does not exploit target task information, and (ii) unlabeled data is only used for sample selection rather than model training. To address these limitations, we introduce novel techniques that significantly improve the use of abundant unlabeled data during training and take into account the task information. Concretely, we propose an improved pseudo-labeling algorithm that leverages information from all unlabeled data in a semi-supervised manner, thus allowing a model to explore a richer data space. In addition, we develop a ranking-based loss prediction module that converts predicted relative ranking information into a differentiable ranking loss. This loss can be embedded as a rank variable into the latent space of a variational autoencoder and then trained with a discriminator in an adversarial fashion for sample selection. We demonstrate the superior performance of our approach over the state of the art on various image classification and segmentation benchmark datasets.
MetaMax: Improved Open-Set Deep Neural Networks via Weibull Calibration
Nov 20, 2022Open-set recognition refers to the problem in which classes that were not seen during training appear at inference time. This requires the ability to identify instances of novel classes while maintaining discriminative capability for closed-set classification. OpenMax was the first deep neural network-based approach to address open-set recognition by calibrating the predictive scores of a standard closed-set classification network. In this paper we present MetaMax, a more effective post-processing technique that improves upon contemporary methods by directly modeling class activation vectors. MetaMax removes the need for computing class mean activation vectors (MAVs) and distances between a query image and a class MAV as required in OpenMax. Experimental results show that MetaMax outperforms OpenMax and is comparable in performance to other state-of-the-art approaches.
Evaluating Uncertainty Calibration for Open-Set Recognition
May 15, 2022



Despite achieving enormous success in predictive accuracy for visual classification problems, deep neural networks (DNNs) suffer from providing overconfident probabilities on out-of-distribution (OOD) data. Yet, accurate uncertainty estimation is crucial for safe and reliable robot autonomy. In this paper, we evaluate popular calibration techniques for open-set conditions in a way that is distinctly different from the conventional evaluation of calibration methods on OOD data. Our results show that closed-set DNN calibration approaches are much less effective for open-set recognition, which highlights the need to develop new DNN calibration methods to address this problem.
An Uncertainty Estimation Framework for Probabilistic Object Detection
Jun 28, 2021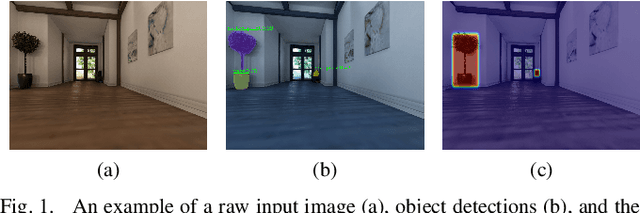



In this paper, we introduce a new technique that combines two popular methods to estimate uncertainty in object detection. Quantifying uncertainty is critical in real-world robotic applications. Traditional detection models can be ambiguous even when they provide a high-probability output. Robot actions based on high-confidence, yet unreliable predictions, may result in serious repercussions. Our framework employs deep ensembles and Monte Carlo dropout for approximating predictive uncertainty, and it improves upon the uncertainty estimation quality of the baseline method. The proposed approach is evaluated on publicly available synthetic image datasets captured from sequences of video.