 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep learning model for Mongolian Citizens Feedback Analysis using Word Vector Embeddings
Feb 23, 2023


A large amount of feedback was collected over the years. Many feedback analysis models have been developed focusing on the English language. Recognizing the concept of feedback is challenging and crucial in languages which do not have applicable corpus and tools employed in Natural Language Processing (i.e., vocabulary corpus, sentence structure rules, etc). However, in this paper, we study a feedback classification in Mongolian language using two different word embeddings for deep learning. We compare the results of proposed approaches. We use feedback data in Cyrillic collected from 2012-2018. The result indicates that word embeddings using their own dataset improve the deep learning based proposed model with the best accuracy of 80.1% and 82.7% for two classification tasks.
Explorative analysis of human disease-symptoms relations using the Convolutional Neural Network
Feb 23, 2023



In the field of health-care and bio-medical research, understanding the relationship between the symptoms of diseases is crucial for early diagnosis and determining hidden relationships between diseases. The study aimed to understand the extent of symptom types in disease prediction tasks. In this research, we analyze a pre-generated symptom-based human disease dataset and demonstrate the degree of predictability for each disease based on the Convolutional Neural Network and the Support Vector Machine. Ambiguity of disease is studied using the K-Means and the Principal Component Analysis. Our results indicate that machine learning can potentially diagnose diseases with the 98-100% accuracy in the early stage, taking the characteristics of symptoms into account. Our result highlights that types of unusual symptoms are a good proxy for disease early identification accurately. We also highlight that unusual symptoms increase the accuracy of the disease prediction task.
Semantic Enrichment of Mobile Phone Data Records Using Background Knowledge
Apr 22, 2015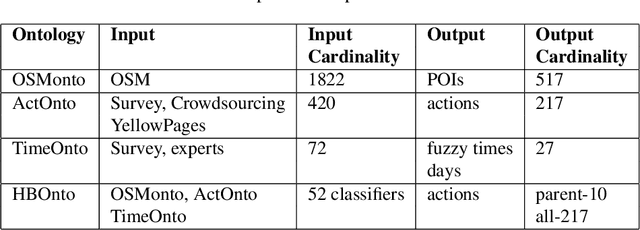
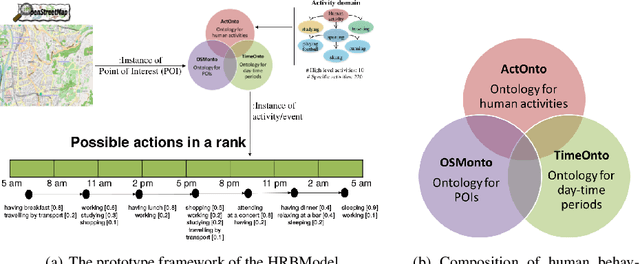
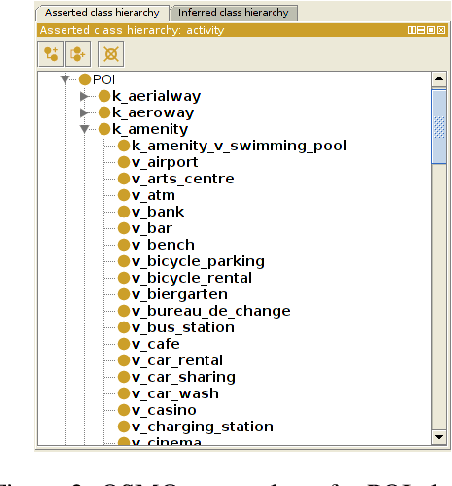
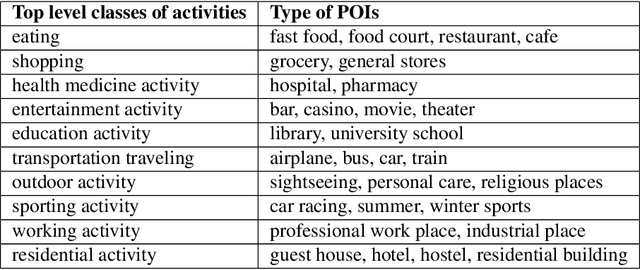
Every day, billions of mobile network events (i.e. CDRs) are generated by cellular phone operator companies. Latent in this data are inspiring insights about human actions and behaviors, the discovery of which is important because context-aware applications and services hold the key to user-driven, intelligent services, which can enhance our everyday lives such as social and economic development, urban planning, and health prevention. The major challenge in this area is that interpreting such a big stream of data requires a deep understanding of mobile network events' context through available background knowledge. This article addresses the issues in context awareness given heterogeneous and uncertain data of mobile network events missing reliable information on the context of this activity. The contribution of this research is a model from a combination of logical and statistical reasoning standpoints for enabling human activity inference in qualitative terms from open geographical data that aimed at improving the quality of human behaviors recognition tasks from CDRs. We use open geographical data, Openstreetmap (OSM), as a proxy for predicting the content of human activity in the area. The user study performed in Trento shows that predicted human activities (top level) match the survey data with around 93% overall accuracy. The extensive validation for predicting a more specific economic type of human activity performed in Barcelona, by employing credit card transaction data. The analysis identifies that appropriately normalized data on points of interest (POI) is a good proxy for predicting human economical activities, with 84% accuracy on average. So the model is proven to be efficient for predicting the context of human activity, when its total level could be efficiently observed from cell phone data records, missing contextual information however.
* 40 pages, 34 figures