 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUne mesure d'expertise pour le crowdsourcing
Jan 17, 2017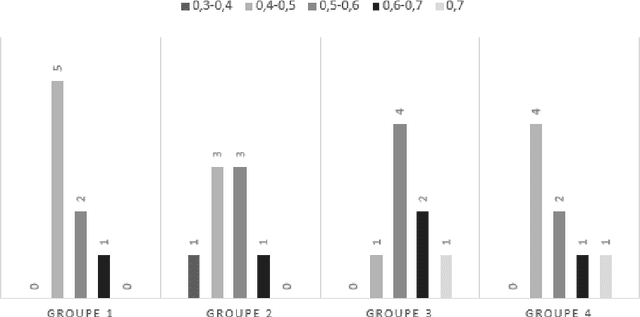
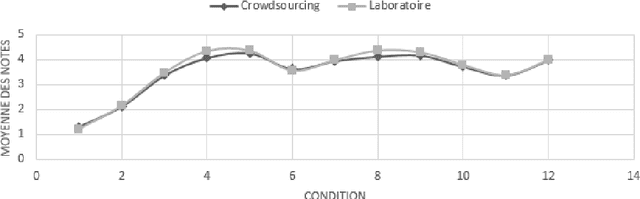
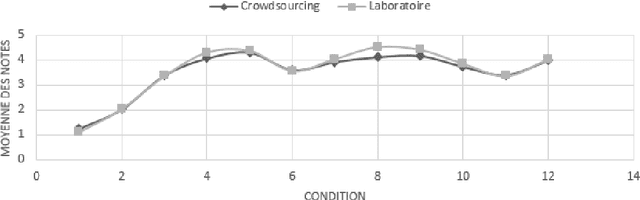
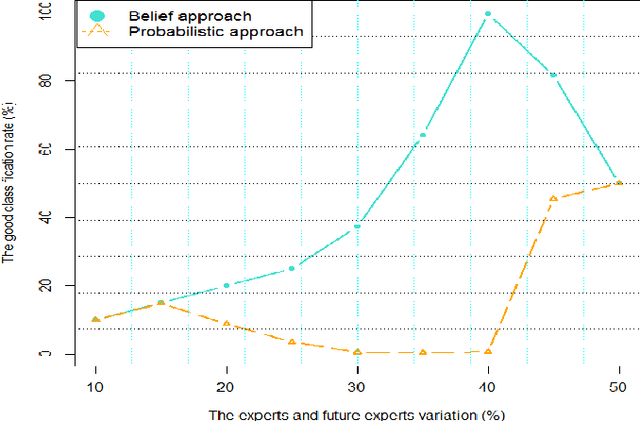
Crowdsourcing, a major economic issue, is the fact that the firm outsources internal task to the crowd. It is a form of digital subcontracting for the general public. The evaluation of the participants work quality is a major issue in crowdsourcing. Indeed, contributions must be controlled to ensure the effectiveness and relevance of the campaign. We are particularly interested in small, fast and not automatable tasks. Several methods have been proposed to solve this problem, but they are applicable when the "golden truth" is not always known. This work has the particularity to propose a method for calculating the degree of expertise in the presence of gold data in crowdsourcing. This method is based on the belief function theory and proposes a structuring of data using graphs. The proposed approach will be assessed and applied to the data.
* in French
Characterization of experts in crowdsourcing platforms
Sep 30, 2016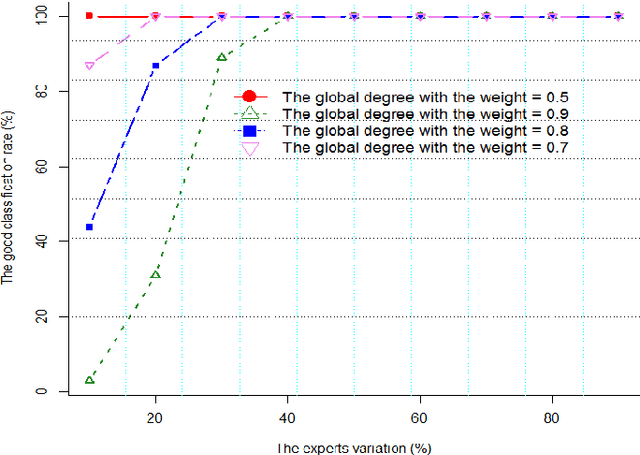
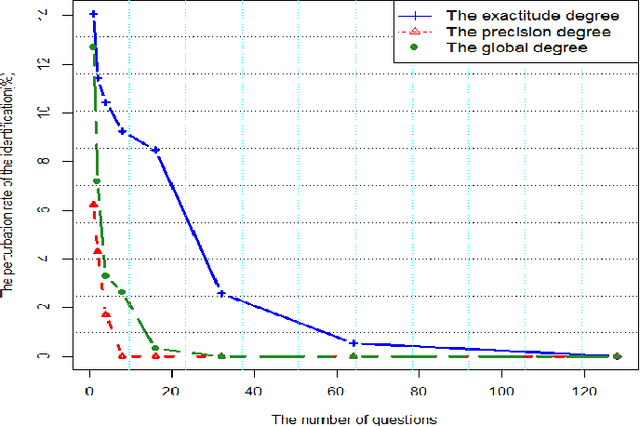
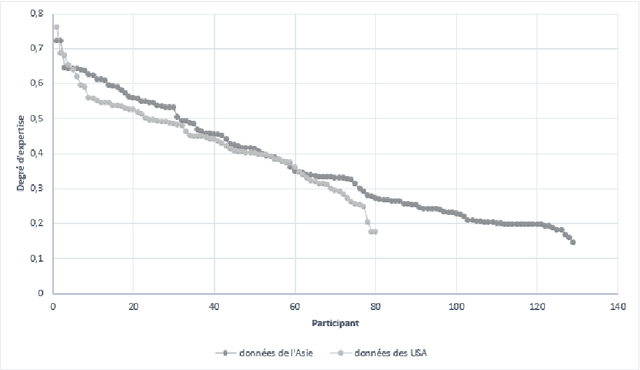
Crowdsourcing platforms enable to propose simple human intelligence tasks to a large number of participants who realise these tasks. The workers often receive a small amount of money or the platforms include some other incentive mechanisms, for example they can increase the workers reputation score, if they complete the tasks correctly. We address the problem of identifying experts among participants, that is, workers, who tend to answer the questions correctly. Knowing who are the reliable workers could improve the quality of knowledge one can extract from responses. As opposed to other works in the literature, we assume that participants can give partial or incomplete responses, in case they are not sure that their answers are correct. We model such partial or incomplete responses with the help of belief functions, and we derive a measure that characterizes the expertise level of each participant. This measure is based on precise and exactitude degrees that represent two parts of the expertise level. The precision degree reflects the reliability level of the participants and the exactitude degree reflects the knowledge level of the participants. We also analyze our model through simulation and demonstrate that our richer model can lead to more reliable identification of experts.