 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQCircuitNet: A Large-Scale Hierarchical Dataset for Quantum Algorithm Design
Oct 10, 2024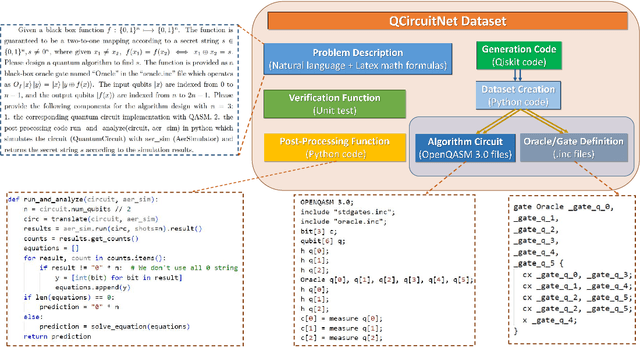



Quantum computing is an emerging field recognized for the significant speedup it offers over classical computing through quantum algorithms. However, designing and implementing quantum algorithms pose challenges due to the complex nature of quantum mechanics and the necessity for precise control over quantum states. Despite the significant advancements in AI, there has been a lack of datasets specifically tailored for this purpose. In this work, we introduce QCircuitNet, the first benchmark and test dataset designed to evaluate AI's capability in designing and implementing quantum algorithms in the form of quantum circuit codes. Unlike using AI for writing traditional codes, this task is fundamentally different and significantly more complicated due to highly flexible design space and intricate manipulation of qubits. Our key contributions include: 1. A general framework which formulates the key features of quantum algorithm design task for Large Language Models. 2. Implementation for a wide range of quantum algorithms from basic primitives to advanced applications, with easy extension to more quantum algorithms. 3. Automatic validation and verification functions, allowing for iterative evaluation and interactive reasoning without human inspection. 4. Promising potential as a training dataset through primitive fine-tuning results. We observed several interesting experimental phenomena: fine-tuning does not always outperform few-shot learning, and LLMs tend to exhibit consistent error patterns. QCircuitNet provides a comprehensive benchmark for AI-driven quantum algorithm design, offering advantages in model evaluation and improvement, while also revealing some limitations of LLMs in this domain.
Enhancing Adversarial Attacks: The Similar Target Method
Sep 06, 2023
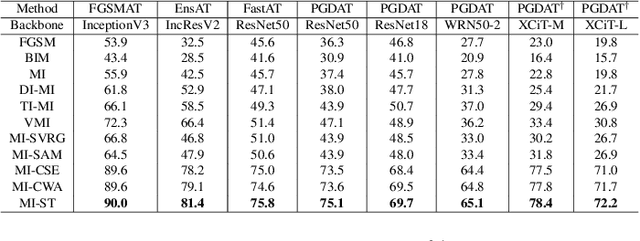
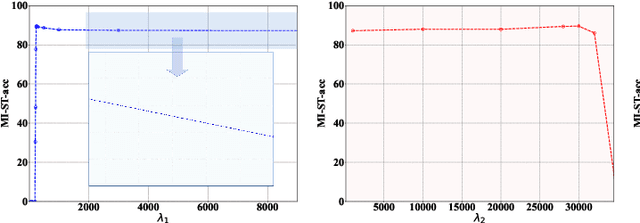
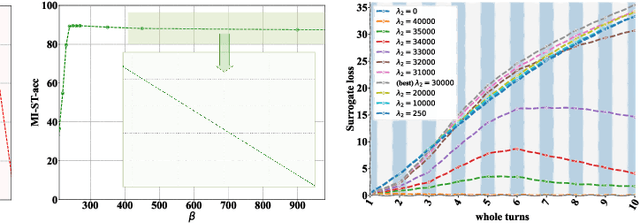
Deep neural networks are vulnerable to adversarial examples, posing a threat to the models' applications and raising security concerns. An intriguing property of adversarial examples is their strong transferability. Several methods have been proposed to enhance transferability, including ensemble attacks which have demonstrated their efficacy. However, prior approaches simply average logits, probabilities, or losses for model ensembling, lacking a comprehensive analysis of how and why model ensembling significantly improves transferability. In this paper, we propose a similar targeted attack method named Similar Target~(ST). By promoting cosine similarity between the gradients of each model, our method regularizes the optimization direction to simultaneously attack all surrogate models. This strategy has been proven to enhance generalization ability. Experimental results on ImageNet validate the effectiveness of our approach in improving adversarial transferability. Our method outperforms state-of-the-art attackers on 18 discriminative classifiers and adversarially trained models.