 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring Fine-Grained Semantic Equivalence with Abstract Meaning Representation
Oct 06, 2022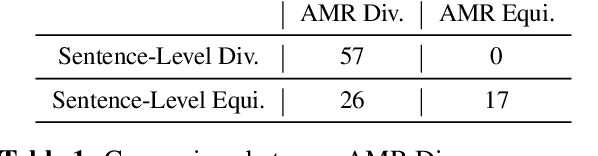
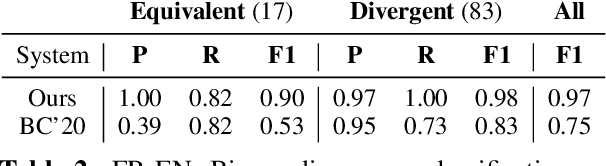

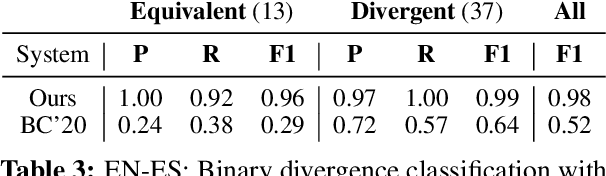
Identifying semantically equivalent sentences is important for many cross-lingual and mono-lingual NLP tasks. Current approaches to semantic equivalence take a loose, sentence-level approach to "equivalence," despite previous evidence that fine-grained differences and implicit content have an effect on human understanding (Roth and Anthonio, 2021) and system performance (Briakou and Carpuat, 2021). In this work, we introduce a novel, more sensitive method of characterizing semantic equivalence that leverages Abstract Meaning Representation graph structures. We develop an approach, which can be used with either gold or automatic AMR annotations, and demonstrate that our solution is in fact finer-grained than existing corpus filtering methods and more accurate at predicting strictly equivalent sentences than existing semantic similarity metrics. We suggest that our finer-grained measure of semantic equivalence could limit the workload in the task of human post-edited machine translation and in human evaluation of sentence similarity.