 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequential Regression for Continuous Value Prediction using Residual Quantization
Feb 26, 2026Continuous value prediction plays a crucial role in industrial-scale recommendation systems, including tasks such as predicting users' watch-time and estimating the gross merchandise value (GMV) in e-commerce transactions. However, it remains challenging due to the highly complex and long-tailed nature of the data distributions. Existing generative approaches rely on rigid parametric distribution assumptions, which fundamentally limits their performance when such assumptions misalign with real-world data. Overly simplified forms cannot adequately model real-world complexities, while more intricate assumptions often suffer from poor scalability and generalization. To address these challenges, we propose a residual quantization (RQ)-based sequence learning framework that represents target continuous values as a sum of ordered quantization codes, predicted recursively from coarse to fine granularity with diminishing quantization errors. We introduce a representation learning objective that aligns RQ code embedding space with the ordinal structure of target values, allowing the model to capture continuous representations for quantization codes and further improving prediction accuracy. We perform extensive evaluations on public benchmarks for lifetime value (LTV) and watch-time prediction, alongside a large-scale online experiment for GMV prediction on an industrial short-video recommendation platform. The results consistently show that our approach outperforms state-of-the-art methods, while demonstrating strong generalization across diverse continuous value prediction tasks in recommendation systems.
Efficient Semi-Supervised Federated Learning for Heterogeneous Participants
Jul 29, 2023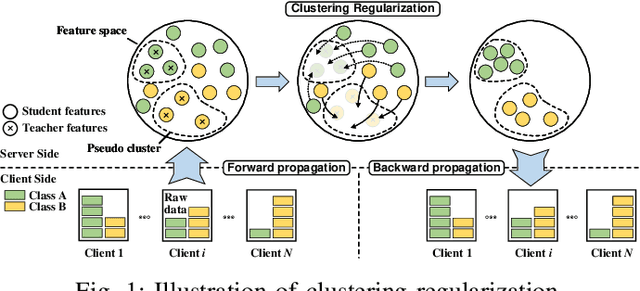
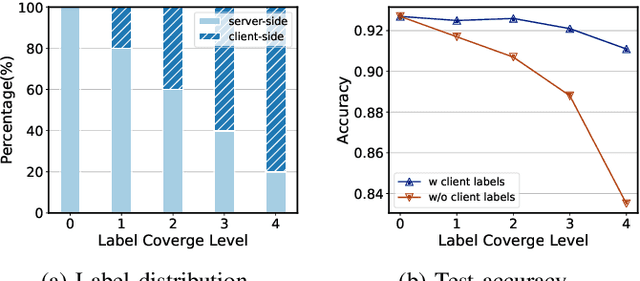
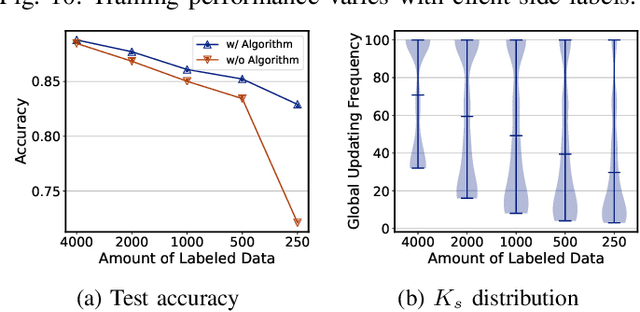
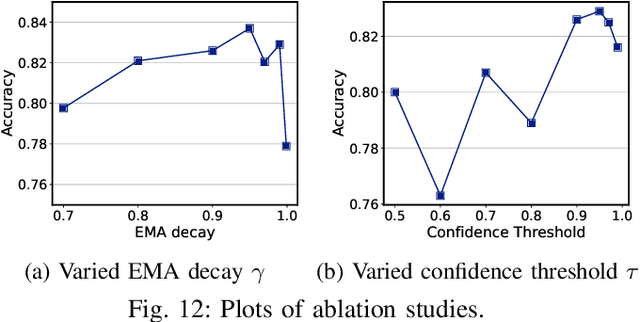
Federated Learning (FL) has emerged to allow multiple clients to collaboratively train machine learning models on their private data. However, training and deploying large models for broader applications is challenging in resource-constrained environments. Fortunately, Split Federated Learning (SFL) offers an excellent solution by alleviating the computation and communication burden on the clients SFL often assumes labeled data for local training on clients, however, it is not the case in practice.Prior works have adopted semi-supervised techniques for leveraging unlabeled data in FL, but data non-IIDness poses another challenge to ensure training efficiency. Herein, we propose Pseudo-Clustering Semi-SFL, a novel system for training models in scenarios where labeled data reside on the server. By introducing Clustering Regularization, model performance under data non-IIDness can be improved. Besides, our theoretical and experimental investigations into model convergence reveal that the inconsistent training processes on labeled and unlabeled data impact the effectiveness of clustering regularization. Upon this, we develop a control algorithm for global updating frequency adaptation, which dynamically adjusts the number of supervised training iterations to mitigate the training inconsistency. Extensive experiments on benchmark models and datasets show that our system provides a 3.3x speed-up in training time and reduces the communication cost by about 80.1% while reaching the target accuracy, and achieves up to 6.9% improvement in accuracy under non-IID scenarios compared to the state-of-the-art.