 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Semi-Supervised Learning Framework for Surgical Gesture Segmentation and Recognition Based on Multi-Modality Data
Jul 31, 2023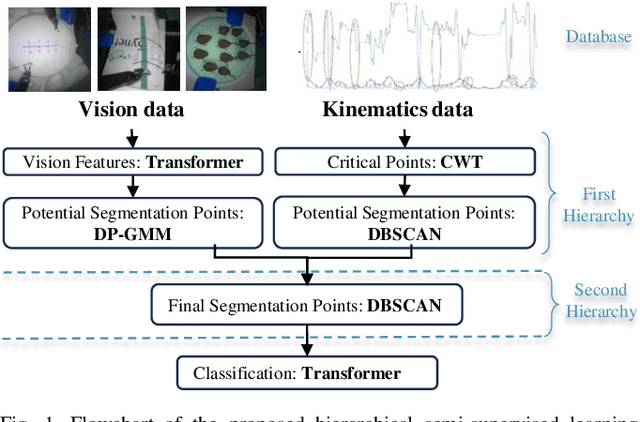
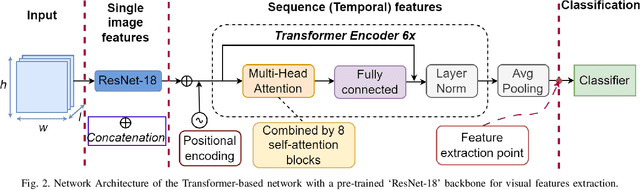
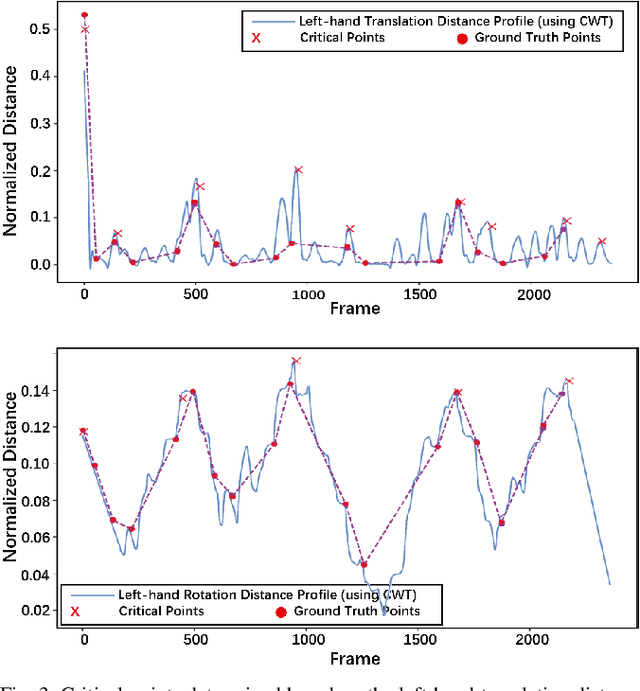

Segmenting and recognizing surgical operation trajectories into distinct, meaningful gestures is a critical preliminary step in surgical workflow analysis for robot-assisted surgery. This step is necessary for facilitating learning from demonstrations for autonomous robotic surgery, evaluating surgical skills, and so on. In this work, we develop a hierarchical semi-supervised learning framework for surgical gesture segmentation using multi-modality data (i.e. kinematics and vision data). More specifically, surgical tasks are initially segmented based on distance characteristics-based profiles and variance characteristics-based profiles constructed using kinematics data. Subsequently, a Transformer-based network with a pre-trained `ResNet-18' backbone is used to extract visual features from the surgical operation videos. By combining the potential segmentation points obtained from both modalities, we can determine the final segmentation points. Furthermore, gesture recognition can be implemented based on supervised learning. The proposed approach has been evaluated using data from the publicly available JIGSAWS database, including Suturing, Needle Passing, and Knot Tying tasks. The results reveal an average F1 score of 0.623 for segmentation and an accuracy of 0.856 for recognition.