 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast System Technology Co-Optimization Framework for Emerging Technology Based on Graph Neural Networks
Apr 10, 2024This paper proposes a fast system technology co-optimization (STCO) framework that optimizes power, performance, and area (PPA) for next-generation IC design, addressing the challenges and opportunities presented by novel materials and device architectures. We focus on accelerating the technology level of STCO using AI techniques, by employing graph neural network (GNN)-based approaches for both TCAD simulation and cell library characterization, which are interconnected through a unified compact model, collectively achieving over a 100X speedup over traditional methods. These advancements enable comprehensive STCO iterations with runtime speedups ranging from 1.9X to 14.1X and supports both emerging and traditional technologies.
Chiplet Placement Order Exploration Based on Learning to Rank with Graph Representation
Apr 07, 2024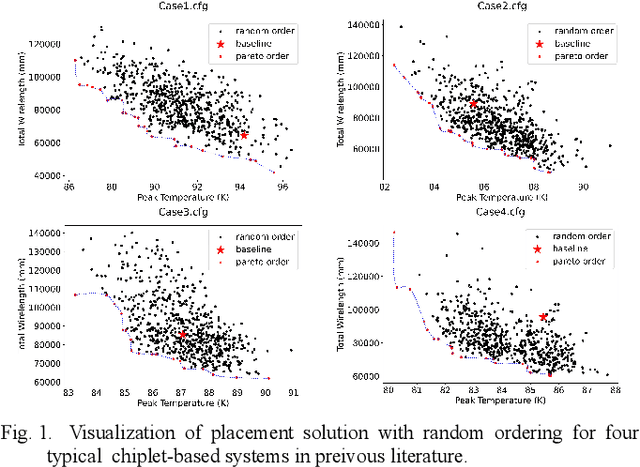
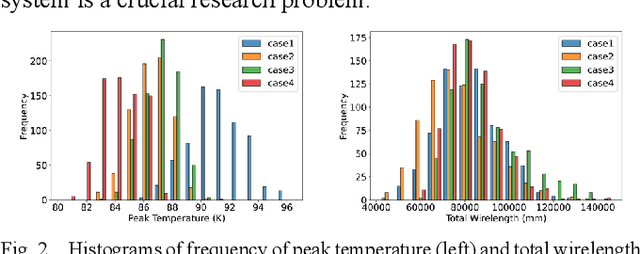
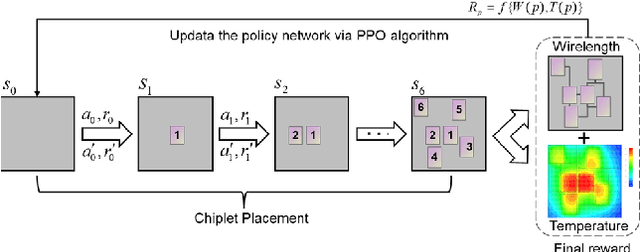
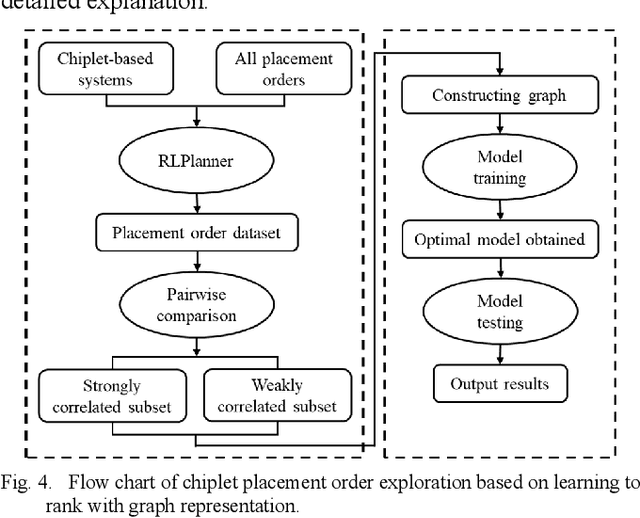
Chiplet-based systems, integrating various silicon dies manufactured at different integrated circuit technology nodes on a carrier interposer, have garnered significant attention in recent years due to their cost-effectiveness and competitive performance. The widespread adoption of reinforcement learning as a sequential placement method has introduced a new challenge in determining the optimal placement order for each chiplet. The order in which chiplets are placed on the interposer influences the spatial resources available for earlier and later placed chiplets, making the placement results highly sensitive to the sequence of chiplet placement. To address these challenges, we propose a learning to rank approach with graph representation, building upon the reinforcement learning framework RLPlanner. This method aims to select the optimal chiplet placement order for each chiplet-based system. Experimental results demonstrate that compared to placement order obtained solely based on the descending order of the chiplet area and the number of interconnect wires between the chiplets, utilizing the placement order obtained from the learning to rank network leads to further improvements in system temperature and inter-chiplet wirelength. Specifically, applying the top-ranked placement order obtained from the learning to rank network results in a 10.05% reduction in total inter-chiplet wirelength and a 1.01% improvement in peak system temperature during the chiplet placement process.
Fast Cell Library Characterization for Design Technology Co-Optimization Based on Graph Neural Networks
Dec 20, 2023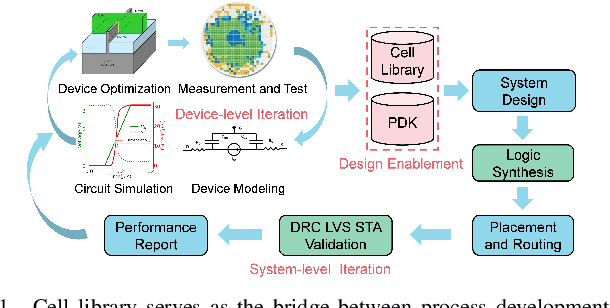
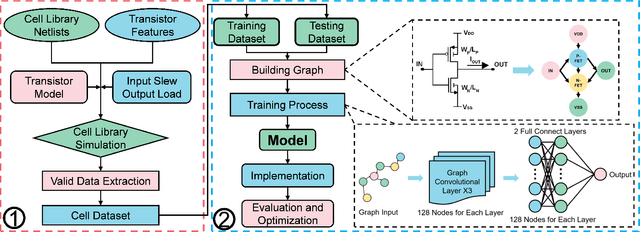
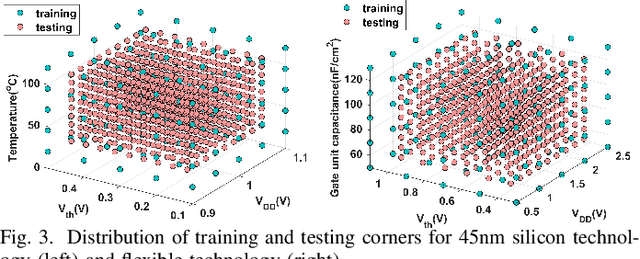
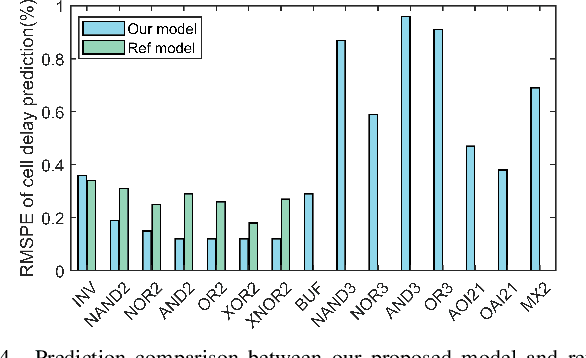
Design technology co-optimization (DTCO) plays a critical role in achieving optimal power, performance, and area (PPA) for advanced semiconductor process development. Cell library characterization is essential in DTCO flow, but traditional methods are time-consuming and costly. To overcome these challenges, we propose a graph neural network (GNN)-based machine learning model for rapid and accurate cell library characterization. Our model incorporates cell structures and demonstrates high prediction accuracy across various process-voltage-temperature (PVT) corners and technology parameters. Validation with 512 unseen technology corners and over one million test data points shows accurate predictions of delay, power, and input pin capacitance for 33 types of cells, with a mean absolute percentage error (MAPE) $\le$ 0.95% and a speed-up of 100X compared with SPICE simulations. Additionally, we investigate system-level metrics such as worst negative slack (WNS), leakage power, and dynamic power using predictions obtained from the GNN-based model on unseen corners. Our model achieves precise predictions, with absolute error $\le$3.0 ps for WNS, percentage errors $\le$0.60% for leakage power, and $\le$0.99% for dynamic power, when compared to golden reference. With the developed model, we further proposed a fine-grained drive strength interpolation methodology to enhance PPA for small-to-medium-scale designs, resulting in an approximate 1-3% improvement.