 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSE-Bridge: Speech Enhancement with Consistent Brownian Bridge
May 23, 2023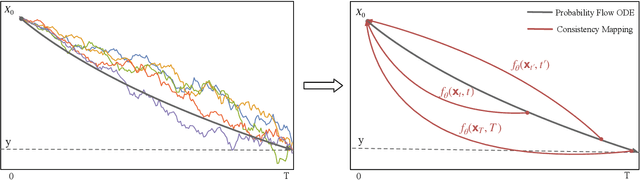
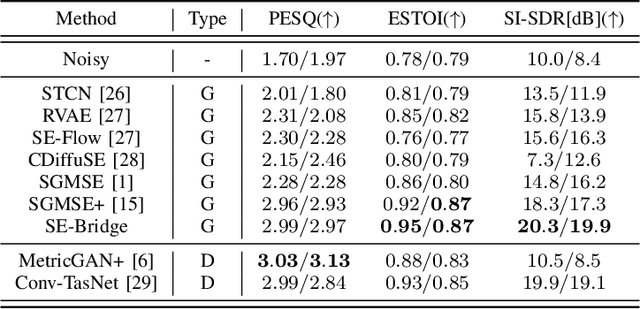
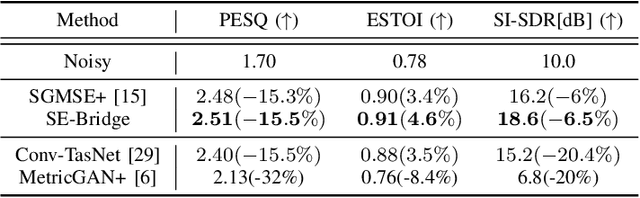
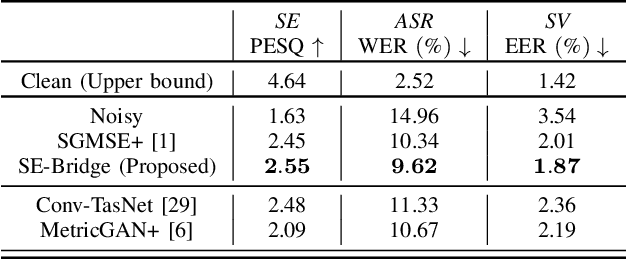
We propose SE-Bridge, a novel method for speech enhancement (SE). After recently applying the diffusion models to speech enhancement, we can achieve speech enhancement by solving a stochastic differential equation (SDE). Each SDE corresponds to a probabilistic flow ordinary differential equation (PF-ODE), and the trajectory of the PF-ODE solution consists of the speech states at different moments. Our approach is based on consistency model that ensure any speech states on the same PF-ODE trajectory, correspond to the same initial state. By integrating the Brownian Bridge process, the model is able to generate high-intelligibility speech samples without adversarial training. This is the first attempt that applies the consistency models to SE task, achieving state-of-the-art results in several metrics while saving 15 x the time required for sampling compared to the diffusion-based baseline. Our experiments on multiple datasets demonstrate the effectiveness of SE-Bridge in SE. Furthermore, we show through extensive experiments on downstream tasks, including Automatic Speech Recognition (ASR) and Speaker Verification (SV), that SE-Bridge can effectively support multiple downstream tasks.
SRTNet: Time Domain Speech Enhancement Via Stochastic Refinement
Oct 30, 2022



Diffusion model, as a new generative model which is very popular in image generation and audio synthesis, is rarely used in speech enhancement. In this paper, we use the diffusion model as a module for stochastic refinement. We propose SRTNet, a novel method for speech enhancement via Stochastic Refinement in complete Time domain. Specifically, we design a joint network consisting of a deterministic module and a stochastic module, which makes up the ``enhance-and-refine'' paradigm. We theoretically demonstrate the feasibility of our method and experimentally prove that our method achieves faster training, faster sampling and higher quality. Our code and enhanced samples are available at https://github.com/zhibinQiu/SRTNet.git.