 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversal Transformer Hawkes Process with Adaptive Recursive Iteration
Dec 29, 2021

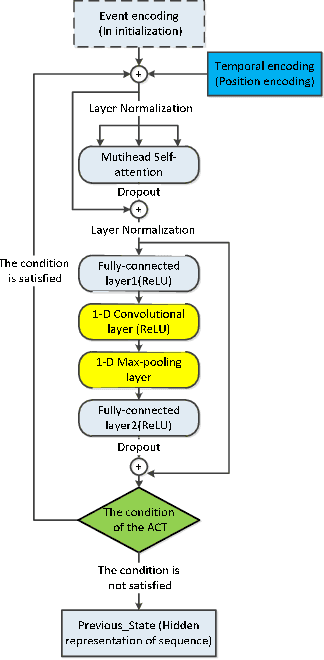

Asynchronous events sequences are widely distributed in the natural world and human activities, such as earthquakes records, users activities in social media and so on. How to distill the information from these seemingly disorganized data is a persistent topic that researchers focus on. The one of the most useful model is the point process model, and on the basis, the researchers obtain many noticeable results. Moreover, in recent years, point process models on the foundation of neural networks, especially recurrent neural networks (RNN) are proposed and compare with the traditional models, their performance are greatly improved. Enlighten by transformer model, which can learning sequence data efficiently without recurrent and convolutional structure, transformer Hawkes process is come out, and achieves state-of-the-art performance. However, there is some research proving that the re-introduction of recursive calculations in transformer can further improve transformers performance. Thus, we come out with a new kind of transformer Hawkes process model, universal transformer Hawkes process (UTHP), which contains both recursive mechanism and self-attention mechanism, and to improve the local perception ability of the model, we also introduce convolutional neural network (CNN) in the position-wise-feed-forward part. We conduct experiments on several datasets to validate the effectiveness of UTHP and explore the changes after the introduction of the recursive mechanism. These experiments on multiple datasets demonstrate that the performance of our proposed new model has a certain improvement compared with the previous state-of-the-art models.
Temporal Attention Augmented Transformer Hawkes Process
Dec 29, 2021



In recent years, mining the knowledge from asynchronous sequences by Hawkes process is a subject worthy of continued attention, and Hawkes processes based on the neural network have gradually become the most hotly researched fields, especially based on the recurrence neural network (RNN). However, these models still contain some inherent shortcomings of RNN, such as vanishing and exploding gradient and long-term dependency problems. Meanwhile, Transformer based on self-attention has achieved great success in sequential modeling like text processing and speech recognition. Although the Transformer Hawkes process (THP) has gained huge performance improvement, THPs do not effectively utilize the temporal information in the asynchronous events, for these asynchronous sequences, the event occurrence instants are as important as the types of events, while conventional THPs simply convert temporal information into position encoding and add them as the input of transformer. With this in mind, we come up with a new kind of Transformer-based Hawkes process model, Temporal Attention Augmented Transformer Hawkes Process (TAA-THP), we modify the traditional dot-product attention structure, and introduce the temporal encoding into attention structure. We conduct numerous experiments on a wide range of synthetic and real-life datasets to validate the performance of our proposed TAA-THP model, significantly improvement compared with existing baseline models on the different measurements is achieved, including log-likelihood on the test dataset, and prediction accuracies of event types and occurrence times. In addition, through the ablation studies, we vividly demonstrate the merit of introducing additional temporal attention by comparing the performance of the model with and without temporal attention.
Tri-Transformer Hawkes Process: Three Heads are better than one
Dec 24, 2021



Abstract. Most of the real world data we encounter are asynchronous event sequence, so the last decades have been characterized by the implementation of various point process into the field of social networks,electronic medical records and financial transactions. At the beginning, Hawkes process and its variants which can simulate simultaneously the self-triggering and mutual triggering patterns between different events in complex sequences in a clear and quantitative way are more popular.Later on, with the advances of neural network, neural Hawkes process has been proposed one after another, and gradually become a research hotspot. The proposal of the transformer Hawkes process (THP) has gained a huge performance improvement, so a new upsurge of the neural Hawkes process based on transformer is set off. However, THP does not make full use of the information of occurrence time and type of event in the asynchronous event sequence. It simply adds the encoding of event type conversion and the location encoding of time conversion to the source encoding. At the same time, the learner built from a single transformer will result in an inescapable learning bias. In order to mitigate these problems, we propose a tri-transformer Hawkes process (Tri-THP) model, in which the event and time information are added to the dot-product attention as auxiliary information to form a new multihead attention. The effectiveness of the Tri-THP is proved by a series of well-designed experiments on both real world and synthetic data.