 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Dynamic Resource Allocation and Client Scheduling in Hierarchical Federated Learning: A Two-Phase Deep Reinforcement Learning Approach
Jun 21, 2024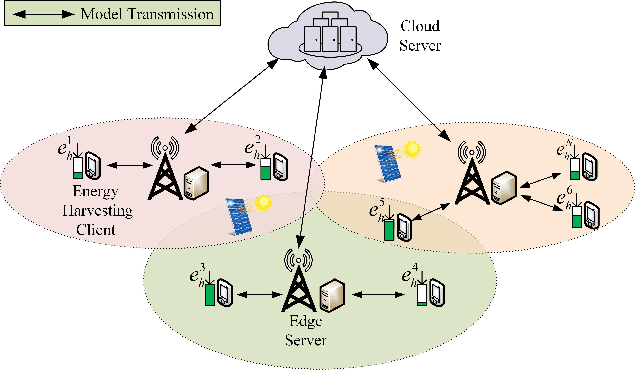
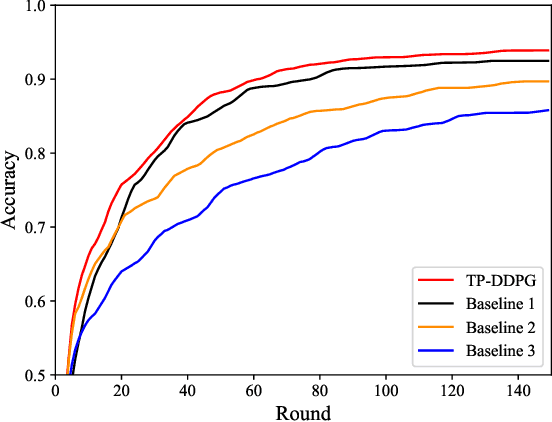
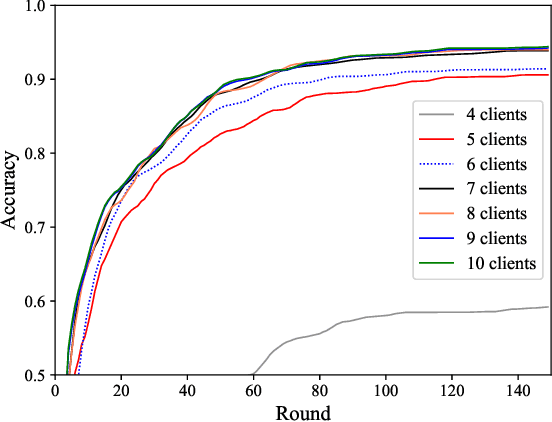
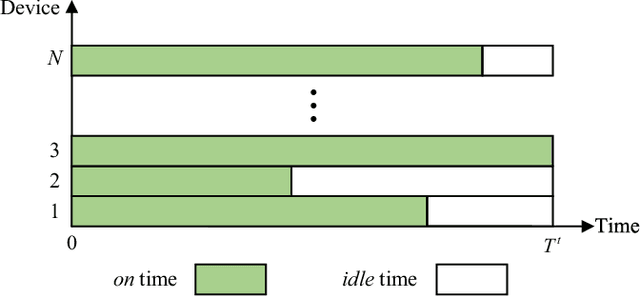
Federated learning (FL) is a viable technique to train a shared machine learning model without sharing data. Hierarchical FL (HFL) system has yet to be studied regrading its multiple levels of energy, computation, communication, and client scheduling, especially when it comes to clients relying on energy harvesting to power their operations. This paper presents a new two-phase deep deterministic policy gradient (DDPG) framework, referred to as ``TP-DDPG'', to balance online the learning delay and model accuracy of an FL process in an energy harvesting-powered HFL system. The key idea is that we divide optimization decisions into two groups, and employ DDPG to learn one group in the first phase, while interpreting the other group as part of the environment to provide rewards for training the DDPG in the second phase. Specifically, the DDPG learns the selection of participating clients, and their CPU configurations and the transmission powers. A new straggler-aware client association and bandwidth allocation (SCABA) algorithm efficiently optimizes the other decisions and evaluates the reward for the DDPG. Experiments demonstrate that with substantially reduced number of learnable parameters, the TP-DDPG can quickly converge to effective polices that can shorten the training time of HFL by 39.4% compared to its benchmarks, when the required test accuracy of HFL is 0.9.