 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompleteDT: Point Cloud Completion with Dense Augment Inference Transformers
May 30, 2022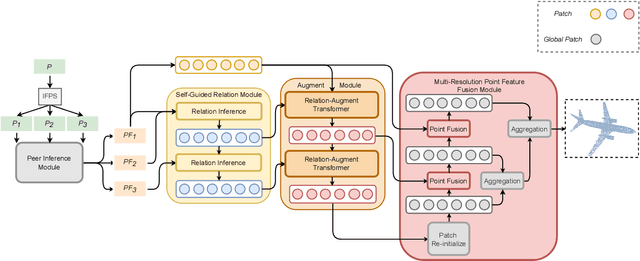



Point cloud completion task aims to predict the missing part of incomplete point clouds and generate complete point clouds with details. In this paper, we propose a novel point cloud completion network, CompleteDT, which is based on the transformer. CompleteDT can learn features within neighborhoods and explore the relationship among these neighborhoods. By sampling the incomplete point cloud to obtain point clouds with different resolutions, we extract features from these point clouds in a self-guided manner, while converting these features into a series of $patches$ based on the geometrical structure. To facilitate transformers to leverage sufficient information about point clouds, we provide a plug-and-play module named Relation-Augment Attention Module (RAA), consisting of Point Cross-Attention Module (PCA) and Point Dense Multi-Scale Attention Module (PDMA). These two modules can enhance the ability to learn features within Patches and consider the correlation among these Patches. Thus, RAA enables to learn structures of incomplete point clouds and contribute to infer the local details of complete point clouds generated. In addition, we predict the complete shape from $patches$ with an efficient generation module, namely, Multi-resolution Point Fusion Module (MPF). MPF gradually generates complete point clouds from $patches$, and updates $patches$ based on these generated point clouds. Experimental results show that our method largely outperforms the state-of-the-art methods.
CT-block: a novel local and global features extractor for point cloud
Nov 30, 2021Deep learning on the point cloud is increasingly developing. Grouping the point with its neighbors and conducting convolution-like operation on them can learn the local feature of the point cloud, but this method is weak to extract the long-distance global feature. Performing the attention-based transformer on the whole point cloud can effectively learn the global feature of it, but this method is hardly to extract the local detailed feature. In this paper, we propose a novel module that can simultaneously extract and fuse local and global features, which is named as CT-block. The CT-block is composed of two branches, where the letter C represents the convolution-branch and the letter T represents the transformer-branch. The convolution-branch performs convolution on the grouped neighbor points to extract the local feature. Meanwhile, the transformer-branch performs offset-attention process on the whole point cloud to extract the global feature. Through the bridge constructed by the feature transmission element in the CT-block, the local and global features guide each other during learning and are fused effectively. We apply the CT-block to construct point cloud classification and segmentation networks, and evaluate the performance of them by several public datasets. The experimental results show that, because the features learned by CT-block are much expressive, the performance of the networks constructed by the CT-block on the point cloud classification and segmentation tasks achieve state of the art.