 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Condensation to Rank Collapse: A Two-Stage Analysis of Transformer Training Dynamics
Oct 08, 2025Although transformer-based models have shown exceptional empirical performance, the fundamental principles governing their training dynamics are inadequately characterized beyond configuration-specific studies. Inspired by empirical evidence showing improved reasoning capabilities under small initialization scales in language models, we employ the gradient flow analytical framework established in [Zhou et al. NeurIPS 2022] to systematically investigate linearized Transformer training dynamics. Our theoretical analysis dissects the dynamics of attention modules into two distinct stages. In the first stage, asymmetric weight perturbations from random initialization sustain non-degenerate gradient dynamics in parameter matrices, facilitating systematic escape from small initialization regimes. Subsequently, these matrices undergo condensation, progressively aligning toward the target orientation. In the second stage, the previously static key-query matrices actively participate in training, driving the normalized matrices toward asymptotic rank collapse. This two-stage framework generalizes classical directional convergence results.
On Multi-Stage Loss Dynamics in Neural Networks: Mechanisms of Plateau and Descent Stages
Nov 06, 2024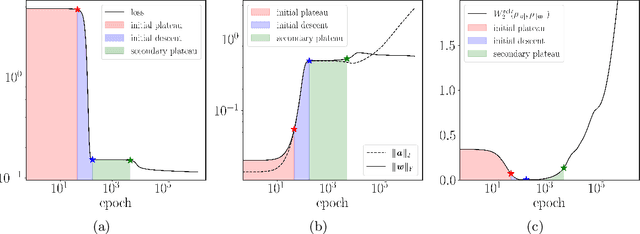
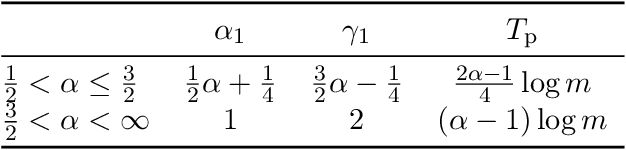
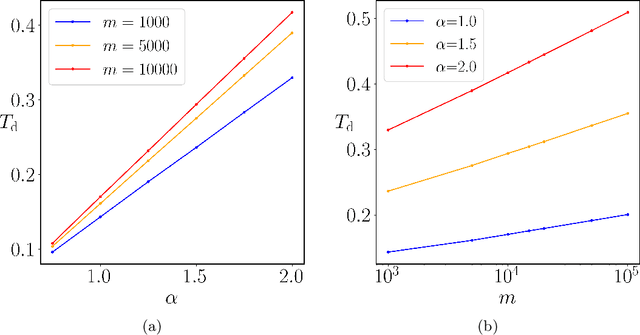
The multi-stage phenomenon in the training loss curves of neural networks has been widely observed, reflecting the non-linearity and complexity inherent in the training process. In this work, we investigate the training dynamics of neural networks (NNs), with particular emphasis on the small initialization regime, identifying three distinct stages observed in the loss curve during training: the initial plateau stage, the initial descent stage, and the secondary plateau stage. Through rigorous analysis, we reveal the underlying challenges contributing to slow training during the plateau stages. While the proof and estimate for the emergence of the initial plateau were established in our previous work, the behaviors of the initial descent and secondary plateau stages had not been explored before. Here, we provide a more detailed proof for the initial plateau, followed by a comprehensive analysis of the initial descent stage dynamics. Furthermore, we examine the factors facilitating the network's ability to overcome the prolonged secondary plateau, supported by both experimental evidence and heuristic reasoning. Finally, to clarify the link between global training trends and local parameter adjustments, we use the Wasserstein distance to track the fine-scale evolution of weight amplitude distribution.
Analyzing Multi-Stage Loss Curve: Plateau and Descent Mechanisms in Neural Networks
Oct 26, 2024The multi-stage phenomenon in the training loss curves of neural networks has been widely observed, reflecting the non-linearity and complexity inherent in the training process. In this work, we investigate the training dynamics of neural networks (NNs), with particular emphasis on the small initialization regime and identify three distinct stages observed in the loss curve during training: initial plateau stage, initial descent stage, and secondary plateau stage. Through rigorous analysis, we reveal the underlying challenges causing slow training during the plateau stages. Building on existing work, we provide a more detailed proof for the initial plateau. This is followed by a comprehensive analysis of the dynamics in the descent stage. Furthermore, we explore the mechanisms that enable the network to overcome the prolonged secondary plateau stage, supported by both experimental evidence and heuristic reasoning. Finally, to better understand the relationship between global training trends and local parameter adjustments, we employ the Wasserstein distance to capture the microscopic evolution of weight amplitude distribution.
On the dynamics of three-layer neural networks: initial condensation
Feb 27, 2024Empirical and theoretical works show that the input weights of two-layer neural networks, when initialized with small values, converge towards isolated orientations. This phenomenon, referred to as condensation, indicates that the gradient descent methods tend to spontaneously reduce the complexity of neural networks during the training process. In this work, we elucidate the mechanisms behind the condensation phenomena occurring in the training of three-layer neural networks and distinguish it from the training of two-layer neural networks. Through rigorous theoretical analysis, we establish the blow-up property of effective dynamics and present a sufficient condition for the occurrence of condensation, findings that are substantiated by experimental results. Additionally, we explore the association between condensation and the low-rank bias observed in deep matrix factorization.