 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovering Operational Patterns Using Image-Based Convolutional Clustering and Composite Evaluation: A Case Study in Foundry Melting Processes
Nov 17, 2025Industrial process monitoring increasingly relies on sensor-generated time-series data, yet the lack of labels, high variability, and operational noise make it difficult to extract meaningful patterns using conventional methods. Existing clustering techniques either rely on fixed distance metrics or deep models designed for static data, limiting their ability to handle dynamic, unstructured industrial sequences. Addressing this gap, this paper proposes a novel framework for unsupervised discovery of operational modes in univariate time-series data using image-based convolutional clustering with composite internal evaluation. The proposed framework improves upon existing approaches in three ways: (1) raw time-series sequences are transformed into grayscale matrix representations via overlapping sliding windows, allowing effective feature extraction using a deep convolutional autoencoder; (2) the framework integrates both soft and hard clustering outputs and refines the selection through a two-stage strategy; and (3) clustering performance is objectively evaluated by a newly developed composite score, S_eva, which combines normalized Silhouette, Calinski-Harabasz, and Davies-Bouldin indices. Applied to over 3900 furnace melting operations from a Nordic foundry, the method identifies seven explainable operational patterns, revealing significant differences in energy consumption, thermal dynamics, and production duration. Compared to classical and deep clustering baselines, the proposed approach achieves superior overall performance, greater robustness, and domain-aligned explainability. The framework addresses key challenges in unsupervised time-series analysis, such as sequence irregularity, overlapping modes, and metric inconsistency, and provides a generalizable solution for data-driven diagnostics and energy optimization in industrial systems.
Multi-Agent Multimodal Large Language Model Framework for Automated Interpretation of Fuel Efficiency Analytics in Public Transportation
Nov 17, 2025Enhancing fuel efficiency in public transportation requires the integration of complex multimodal data into interpretable, decision-relevant insights. However, traditional analytics and visualization methods often yield fragmented outputs that demand extensive human interpretation, limiting scalability and consistency. This study presents a multi-agent framework that leverages multimodal large language models (LLMs) to automate data narration and energy insight generation. The framework coordinates three specialized agents, including a data narration agent, an LLM-as-a-judge agent, and an optional human-in-the-loop evaluator, to iteratively transform analytical artifacts into coherent, stakeholder-oriented reports. The system is validated through a real-world case study on public bus transportation in Northern Jutland, Denmark, where fuel efficiency data from 4006 trips are analyzed using Gaussian Mixture Model clustering. Comparative experiments across five state-of-the-art LLMs and three prompting paradigms identify GPT-4.1 mini with Chain-of-Thought prompting as the optimal configuration, achieving 97.3% narrative accuracy while balancing interpretability and computational cost. The findings demonstrate that multi-agent orchestration significantly enhances factual precision, coherence, and scalability in LLM-based reporting. The proposed framework establishes a replicable and domain-adaptive methodology for AI-driven narrative generation and decision support in energy informatics.
Uncovering Causal Drivers of Energy Efficiency for Industrial Process in Foundry via Time-Series Causal Inference
Nov 17, 2025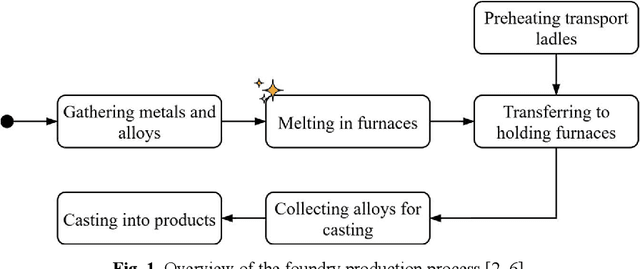

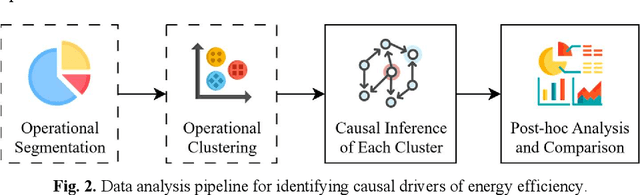
Improving energy efficiency in industrial foundry processes is a critical challenge, as these operations are highly energy-intensive and marked by complex interdependencies among process variables. Correlation-based analyses often fail to distinguish true causal drivers from spurious associations, limiting their usefulness for decision-making. This paper applies a time-series causal inference framework to identify the operational factors that directly affect energy efficiency in induction furnace melting. Using production data from a Danish foundry, the study integrates time-series clustering to segment melting cycles into distinct operational modes with the PCMCI+ algorithm, a state-of-the-art causal discovery method, to uncover cause-effect relationships within each mode. Across clusters, robust causal relations among energy consumption, furnace temperature, and material weight define the core drivers of efficiency, while voltage consistently influences cooling water temperature with a delayed response. Cluster-specific differences further distinguish operational regimes: efficient clusters are characterized by stable causal structures, whereas inefficient ones exhibit reinforcing feedback loops and atypical dependencies. The contributions of this study are twofold. First, it introduces an integrated clustering-causal inference pipeline as a methodological innovation for analyzing energy-intensive processes. Second, it provides actionable insights that enable foundry operators to optimize performance, reduce energy consumption, and lower emissions.
A Visual Diagnostics Framework for District Heating Data: Enhancing Data Quality for AI-Driven Heat Consumption Prediction
Oct 01, 2025High-quality data is a prerequisite for training reliable Artificial Intelligence (AI) models in the energy domain. In district heating networks, sensor and metering data often suffer from noise, missing values, and temporal inconsistencies, which can significantly degrade model performance. This paper presents a systematic approach for evaluating and improving data quality using visual diagnostics, implemented through an interactive web-based dashboard. The dashboard employs Python-based visualization techniques, including time series plots, heatmaps, box plots, histograms, correlation matrices, and anomaly-sensitive KPIs such as skewness and anomaly detection based on the modified z-scores. These tools al-low human experts to inspect and interpret data anomalies, enabling a human-in-the-loop strategy for data quality assessment. The methodology is demonstrated on a real-world dataset from a Danish district heating provider, covering over four years of hourly data from nearly 7000 meters. The findings show how visual analytics can uncover systemic data issues and, in the future, guide data cleaning strategies that enhance the accuracy, stability, and generalizability of Long Short-Term Memory and Gated Recurrent Unit models for heat demand forecasting. The study contributes to a scalable, generalizable framework for visual data inspection and underlines the critical role of data quality in AI-driven energy management systems.
DataPro -- A Standardized Data Understanding and Processing Procedure: A Case Study of an Eco-Driving Project
Jan 21, 2025A systematic pipeline for data processing and knowledge discovery is essential to extracting knowledge from big data and making recommendations for operational decision-making. The CRISP-DM model is the de-facto standard for developing data-mining projects in practice. However, advancements in data processing technologies require enhancements to this framework. This paper presents the DataPro (a standardized data understanding and processing procedure) model, which extends CRISP-DM and emphasizes the link between data scientists and stakeholders by adding the "technical understanding" and "implementation" phases. Firstly, the "technical understanding" phase aligns business demands with technical requirements, ensuring the technical team's accurate comprehension of business goals. Next, the "implementation" phase focuses on the practical application of developed data science models, ensuring theoretical models are effectively applied in business contexts. Furthermore, clearly defining roles and responsibilities in each phase enhances management and communication among all participants. Afterward, a case study on an eco-driving data science project for fuel efficiency analysis in the Danish public transportation sector illustrates the application of the DataPro model. By following the proposed framework, the project identified key business objectives, translated them into technical requirements, and developed models that provided actionable insights for reducing fuel consumption. Finally, the model is evaluated qualitatively, demonstrating its superiority over other data science procedures.
A Novel Hybrid Feature Importance and Feature Interaction Detection Framework for Predictive Optimization in Industry 4.0 Applications
Mar 04, 2024Advanced machine learning algorithms are increasingly utilized to provide data-based prediction and decision-making support in Industry 4.0. However, the prediction accuracy achieved by the existing models is insufficient to warrant practical implementation in real-world applications. This is because not all features present in real-world datasets possess a direct relevance to the predictive analysis being conducted. Consequently, the careful incorporation of select features has the potential to yield a substantial positive impact on the outcome. To address the research gap, this paper proposes a novel hybrid framework that combines the feature importance detector - local interpretable model-agnostic explanations (LIME) and the feature interaction detector - neural interaction detection (NID), to improve prediction accuracy. By applying the proposed framework, unnecessary features can be eliminated, and interactions are encoded to generate a more conducive dataset for predictive purposes. Subsequently, the proposed model is deployed to refine the prediction of electricity consumption in foundry processing. The experimental outcomes reveal an augmentation of up to 9.56% in the R2 score, and a diminution of up to 24.05% in the root mean square error.