 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAblation Based Counterfactuals
Jun 12, 2024



Diffusion models are a class of generative models that generate high-quality samples, but at present it is difficult to characterize how they depend upon their training data. This difficulty raises scientific and regulatory questions, and is a consequence of the complexity of diffusion models and their sampling process. To analyze this dependence, we introduce Ablation Based Counterfactuals (ABC), a method of performing counterfactual analysis that relies on model ablation rather than model retraining. In our approach, we train independent components of a model on different but overlapping splits of a training set. These components are then combined into a single model, from which the causal influence of any training sample can be removed by ablating a combination of model components. We demonstrate how we can construct a model like this using an ensemble of diffusion models. We then use this model to study the limits of training data attribution by enumerating full counterfactual landscapes, and show that single source attributability diminishes with increasing training data size. Finally, we demonstrate the existence of unattributable samples.
Measuring the Success of Diffusion Models at Imitating Human Artists
Jul 08, 2023



Modern diffusion models have set the state-of-the-art in AI image generation. Their success is due, in part, to training on Internet-scale data which often includes copyrighted work. This prompts questions about the extent to which these models learn from, imitate, or copy the work of human artists. This work suggests that tying copyright liability to the capabilities of the model may be useful given the evolving ecosystem of generative models. Specifically, much of the legal analysis of copyright and generative systems focuses on the use of protected data for training. As a result, the connections between data, training, and the system are often obscured. In our approach, we consider simple image classification techniques to measure a model's ability to imitate specific artists. Specifically, we use Contrastive Language-Image Pretrained (CLIP) encoders to classify images in a zero-shot fashion. Our process first prompts a model to imitate a specific artist. Then, we test whether CLIP can be used to reclassify the artist (or the artist's work) from the imitation. If these tests match the imitation back to the original artist, this suggests the model can imitate that artist's expression. Our approach is simple and quantitative. Furthermore, it uses standard techniques and does not require additional training. We demonstrate our approach with an audit of Stable Diffusion's capacity to imitate 70 professional digital artists with copyrighted work online. When Stable Diffusion is prompted to imitate an artist from this set, we find that the artist can be identified from the imitation with an average accuracy of 81.0%. Finally, we also show that a sample of the artist's work can be matched to these imitation images with a high degree of statistical reliability. Overall, these results suggest that Stable Diffusion is broadly successful at imitating individual human artists.
Training Data Attribution for Diffusion Models
Jun 03, 2023Diffusion models have become increasingly popular for synthesizing high-quality samples based on training datasets. However, given the oftentimes enormous sizes of the training datasets, it is difficult to assess how training data impact the samples produced by a trained diffusion model. The difficulty of relating diffusion model inputs and outputs poses significant challenges to model explainability and training data attribution. Here we propose a novel solution that reveals how training data influence the output of diffusion models through the use of ensembles. In our approach individual models in an encoded ensemble are trained on carefully engineered splits of the overall training data to permit the identification of influential training examples. The resulting model ensembles enable efficient ablation of training data influence, allowing us to assess the impact of training data on model outputs. We demonstrate the viability of these ensembles as generative models and the validity of our approach to assessing influence.
Constrained Submodular Optimization for Vaccine Design
Jun 16, 2022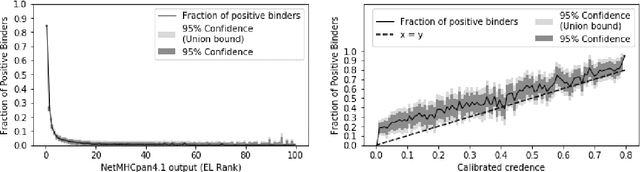
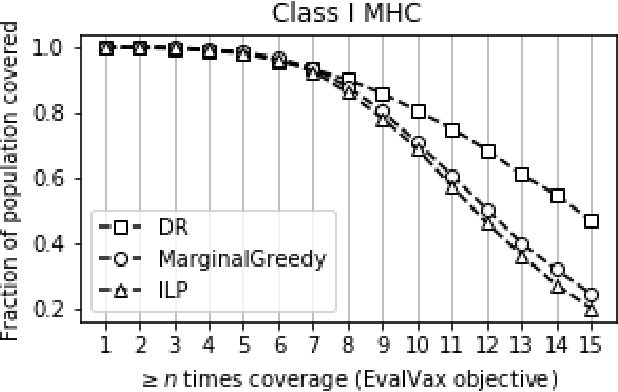
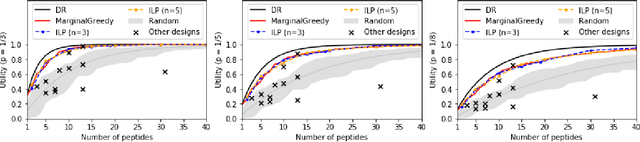
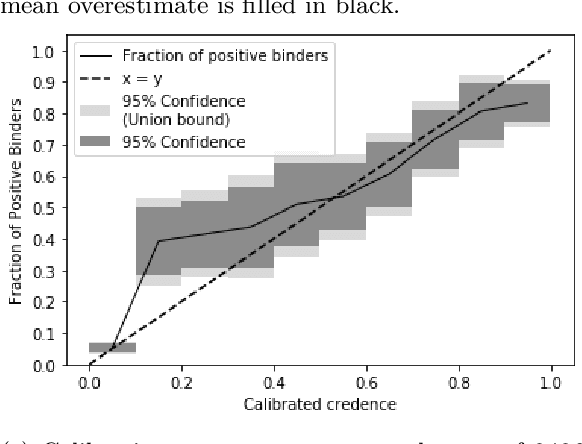
Advances in machine learning have enabled the prediction of immune system responses to prophylactic and therapeutic vaccines. However, the engineering task of designing vaccines remains a challenge. In particular, the genetic variability of the human immune system makes it difficult to design peptide vaccines that provide widespread immunity in vaccinated populations. We introduce a framework for evaluating and designing peptide vaccines that uses probabilistic machine learning models, and demonstrate its ability to produce designs for a SARS-CoV-2 vaccine that outperform previous designs. We provide a theoretical analysis of the approximability, scalability, and complexity of our framework.
Image classifiers can not be made robust to small perturbations
Dec 07, 2021
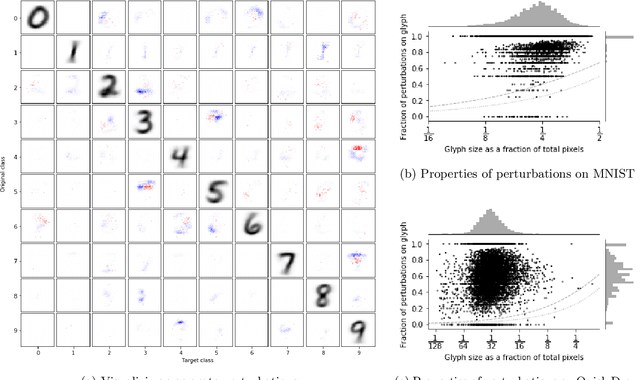
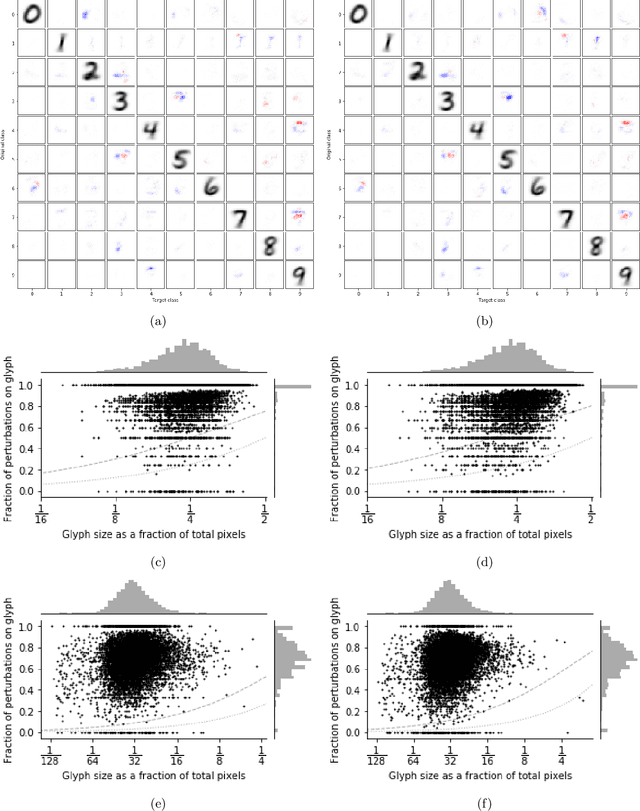
The sensitivity of image classifiers to small perturbations in the input is often viewed as a defect of their construction. We demonstrate that this sensitivity is a fundamental property of classifiers. For any arbitrary classifier over the set of $n$-by-$n$ images, we show that for all but one class it is possible to change the classification of all but a tiny fraction of the images in that class with a tiny modification compared to the diameter of the image space when measured in any $p$-norm, including the hamming distance. We then examine how this phenomenon manifests in human visual perception and discuss its implications for the design considerations of computer vision systems.