 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Model-Blind Temporal Denoisers without Ground Truths
Jul 07, 2020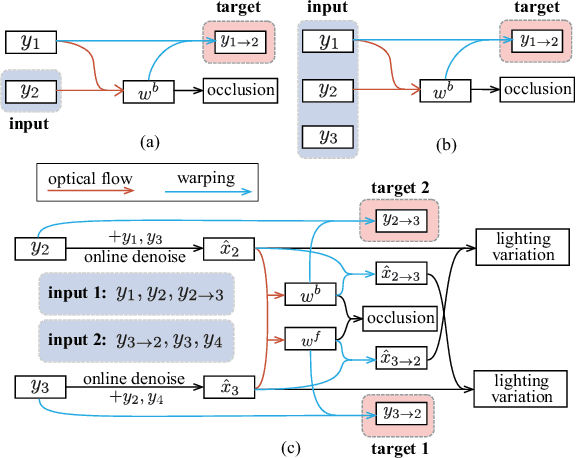
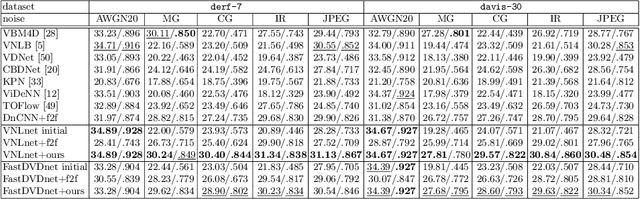


Denoisers trained with synthetic data often fail to cope with the diversity of unknown noises, giving way to methods that can adapt to existing noise without knowing its ground truth. Previous image-based method leads to noise overfitting if directly applied to video denoisers, and has inadequate temporal information management especially in terms of occlusion and lighting variation, which considerably hinders its denoising performance. In this paper, we propose a general framework for video denoising networks that successfully addresses these challenges. A novel twin sampler assembles training data by decoupling inputs from targets without altering semantics, which not only effectively solves the noise overfitting problem, but also generates better occlusion masks efficiently by checking optical flow consistency. An online denoising scheme and a warping loss regularizer are employed for better temporal alignment. Lighting variation is quantified based on the local similarity of aligned frames. Our method consistently outperforms the prior art by 0.6-3.2dB PSNR on multiple noises, datasets and network architectures. State-of-the-art results on reducing model-blind video noises are achieved. Extensive ablation studies are conducted to demonstrate the significance of each technical components.