 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Emergence of Altruism in Large-Language-Model Agents Society
Sep 26, 2025Leveraging Large Language Models (LLMs) for social simulation is a frontier in computational social science. Understanding the social logics these agents embody is critical to this attempt. However, existing research has primarily focused on cooperation in small-scale, task-oriented games, overlooking how altruism, which means sacrificing self-interest for collective benefit, emerges in large-scale agent societies. To address this gap, we introduce a Schelling-variant urban migration model that creates a social dilemma, compelling over 200 LLM agents to navigate an explicit conflict between egoistic (personal utility) and altruistic (system utility) goals. Our central finding is a fundamental difference in the social tendencies of LLMs. We identify two distinct archetypes: "Adaptive Egoists", which default to prioritizing self-interest but whose altruistic behaviors significantly increase under the influence of a social norm-setting message board; and "Altruistic Optimizers", which exhibit an inherent altruistic logic, consistently prioritizing collective benefit even at a direct cost to themselves. Furthermore, to qualitatively analyze the cognitive underpinnings of these decisions, we introduce a method inspired by Grounded Theory to systematically code agent reasoning. In summary, this research provides the first evidence of intrinsic heterogeneity in the egoistic and altruistic tendencies of different LLMs. We propose that for social simulation, model selection is not merely a matter of choosing reasoning capability, but of choosing an intrinsic social action logic. While "Adaptive Egoists" may offer a more suitable choice for simulating complex human societies, "Altruistic Optimizers" are better suited for modeling idealized pro-social actors or scenarios where collective welfare is the primary consideration.
Mitigating Filter Bubbles within Deep Recommender Systems
Sep 16, 2022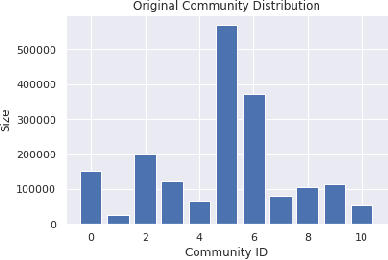


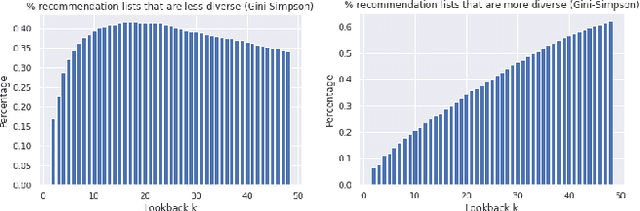
Recommender systems, which offer personalized suggestions to users, power many of today's social media, e-commerce and entertainment. However, these systems have been known to intellectually isolate users from a variety of perspectives, or cause filter bubbles. In our work, we characterize and mitigate this filter bubble effect. We do so by classifying various datapoints based on their user-item interaction history and calculating the influences of the classified categories on each other using the well known TracIn method. Finally, we mitigate this filter bubble effect without compromising accuracy by carefully retraining our recommender system.
Alice's Adventures in the Markovian World
Jul 21, 2019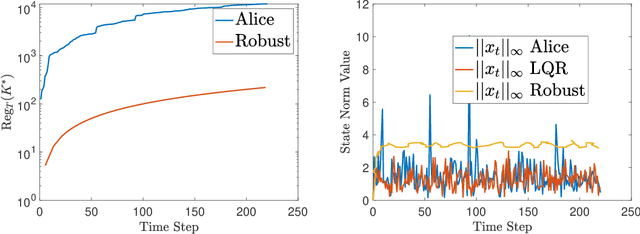
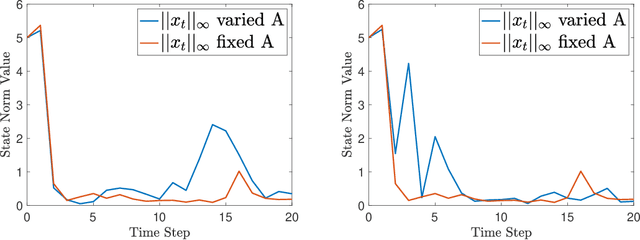
This paper proposes an algorithm Alice having no access to the physics law of the environment, which is actually linear with stochastic noise, and learns to make decisions directly online without a training phase or a stable policy as initial input. Neither estimating the system parameters nor the value functions online, the proposed algorithm generalizes one of the most fundamental online learning algorithms Follow-the-Leader into a linear Gauss-Markov process setting, with a regularization term similar to the momentum method in the gradient descent algorithm, and a feasible online constraint inspired by Lyapunov's Second Theorem. The proposed algorithm is considered as a mirror optimization to the model predictive control. Only knowing the state-action alignment relationship, with the ability to observe every state exactly, a no-regret proof of the algorithm without state noise is given. The analysis of the general linear system with stochastic noise is shown with a sufficient condition for the no-regret proof. The simulations compare the performance of Alice with another recent work and verify the great flexibility of Alice.