 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBioVerge: A Comprehensive Benchmark and Study of Self-Evaluating Agents for Biomedical Hypothesis Generation
Nov 12, 2025Hypothesis generation in biomedical research has traditionally centered on uncovering hidden relationships within vast scientific literature, often using methods like Literature-Based Discovery (LBD). Despite progress, current approaches typically depend on single data types or predefined extraction patterns, which restricts the discovery of novel and complex connections. Recent advances in Large Language Model (LLM) agents show significant potential, with capabilities in information retrieval, reasoning, and generation. However, their application to biomedical hypothesis generation has been limited by the absence of standardized datasets and execution environments. To address this, we introduce BioVerge, a comprehensive benchmark, and BioVerge Agent, an LLM-based agent framework, to create a standardized environment for exploring biomedical hypothesis generation at the frontier of existing scientific knowledge. Our dataset includes structured and textual data derived from historical biomedical hypotheses and PubMed literature, organized to support exploration by LLM agents. BioVerge Agent utilizes a ReAct-based approach with distinct Generation and Evaluation modules that iteratively produce and self-assess hypothesis proposals. Through extensive experimentation, we uncover key insights: 1) different architectures of BioVerge Agent influence exploration diversity and reasoning strategies; 2) structured and textual information sources each provide unique, critical contexts that enhance hypothesis generation; and 3) self-evaluation significantly improves the novelty and relevance of proposed hypotheses.
CTSyn: A Foundational Model for Cross Tabular Data Generation
Jun 07, 2024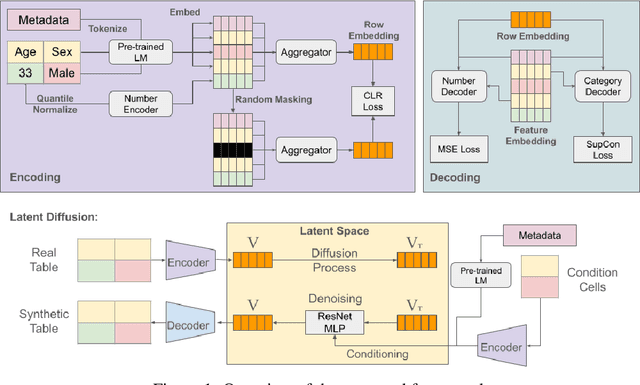
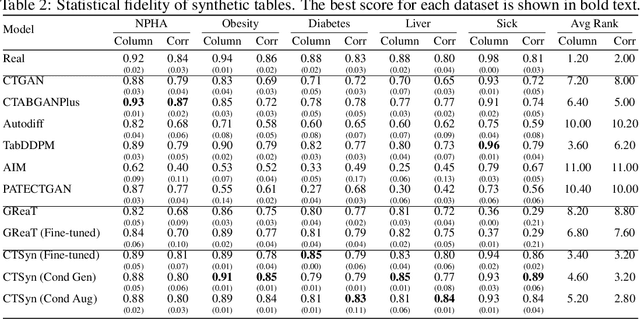
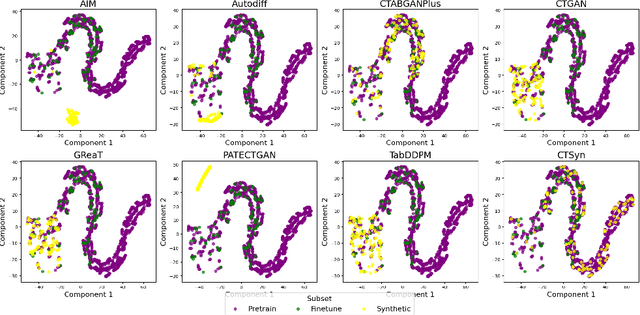
Generative Foundation Models (GFMs) have produced synthetic data with remarkable quality in modalities such as images and text. However, applying GFMs to tabular data poses significant challenges due to the inherent heterogeneity of table features. Existing cross-table learning frameworks are hindered by the absence of both a generative model backbone and a decoding mechanism for heterogeneous feature values. To overcome these limitations, we introduce the Cross-Table Synthesizer (CTSyn), a diffusion-based foundational model tailored for tabular data generation. CTSyn introduces three major components: an aggregator that consolidates heterogeneous tables into a unified latent space; a conditional latent diffusion model for sampling from this space; and type-specific decoders that reconstruct values of varied data types from sampled latent vectors. Extensive testing on real-world datasets reveals that CTSyn not only significantly outperforms existing table synthesizers in utility and diversity, but also uniquely enhances performances of downstream machine learning beyond what is achievable with real data, thus establishing a new paradigm for synthetic data generation.
Mitigating Filter Bubbles within Deep Recommender Systems
Sep 16, 2022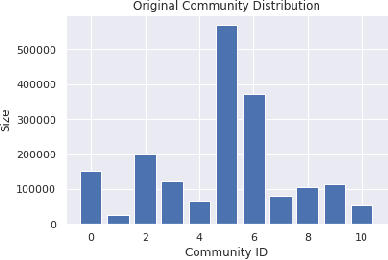


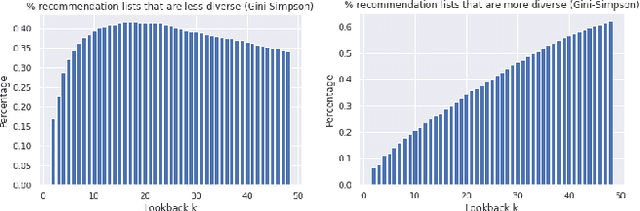
Recommender systems, which offer personalized suggestions to users, power many of today's social media, e-commerce and entertainment. However, these systems have been known to intellectually isolate users from a variety of perspectives, or cause filter bubbles. In our work, we characterize and mitigate this filter bubble effect. We do so by classifying various datapoints based on their user-item interaction history and calculating the influences of the classified categories on each other using the well known TracIn method. Finally, we mitigate this filter bubble effect without compromising accuracy by carefully retraining our recommender system.