 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRPM-Net Reciprocal Point MLP Network for Unknown Network Security Threat Detection
Apr 08, 2026Effective detection of unknown network security threats in multi-class imbalanced environments is critical for maintaining cyberspace security. Current methods focus on learning class representations but face challenges with unknown threat detection, class imbalance, and lack of interpretability, limiting their practical use. To address this, we propose RPM-Net, a novel framework that introduces reciprocal point mechanism to learn "non-class" representations for each known attack category, coupled with adversarial margin constraints that provide geometric interpretability for unknown threat detection. RPM-Net++ further enhances performance through Fisher discriminant regularization. Experimental results show that RPM-Net achieves superior performance across multiple metrics including F1-score, AUROC, and AUPR-OUT, significantly outperforming existing methods and offering practical value for real-world network security applications. Our code is available at:https://github.com/chiachen-chang/RPM-Net
Intrinsic Wrapped Gaussian Process Regression Modeling for Manifold-valued Response Variable
Nov 28, 2024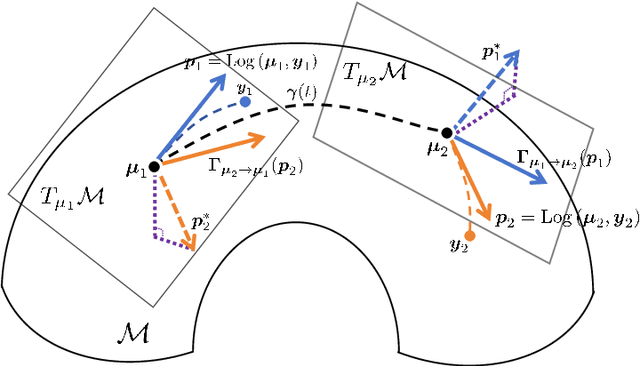
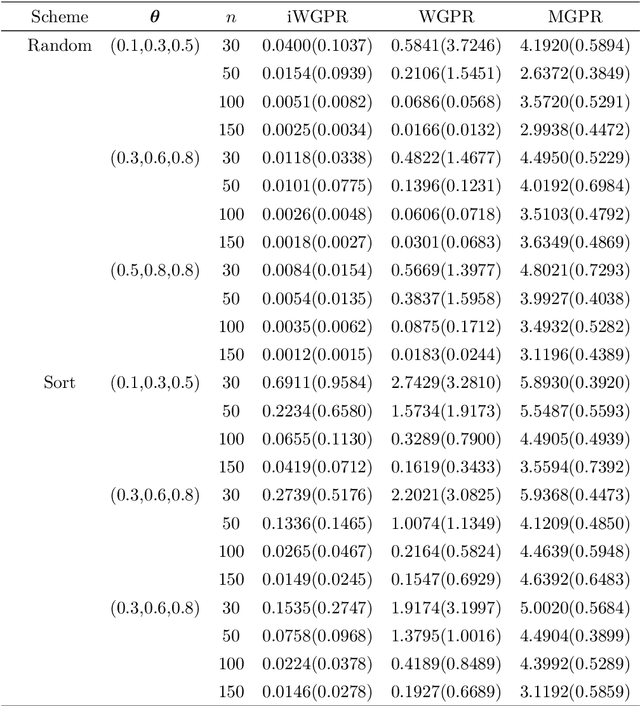
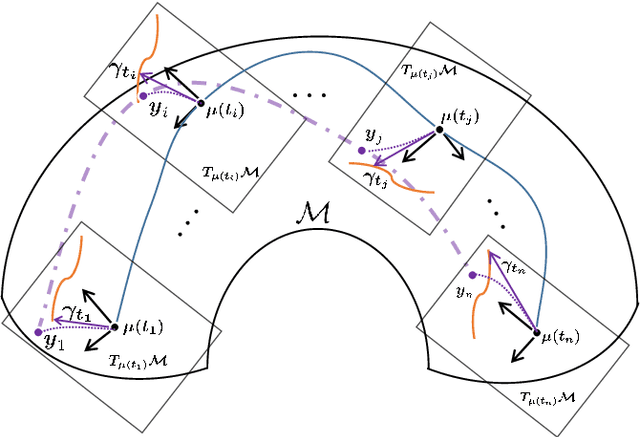
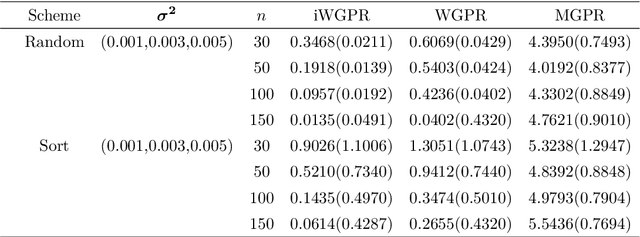
In this paper, we propose a novel intrinsic wrapped Gaussian process regression model for response variable measured on Riemannian manifold. We apply the parallel transport operator to define an intrinsic covariance structure addressing a critical aspect of constructing a well defined Gaussian process regression model. We show that the posterior distribution of regression function is invariant to the choice of orthonormal frames for the coordinate representations of the covariance function. This method can be applied to data situated not only on Euclidean submanifolds but also on manifolds without a natural ambient space. The asymptotic properties for estimating the posterior distribution is established. Numerical studies, including simulation and real-world examples, indicate that the proposed method delivers strong performance.
Active learning for binary classification with variable selection
Jan 29, 2019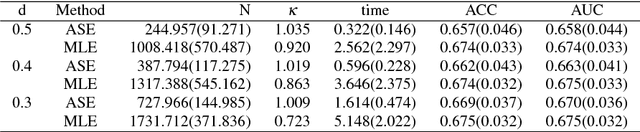
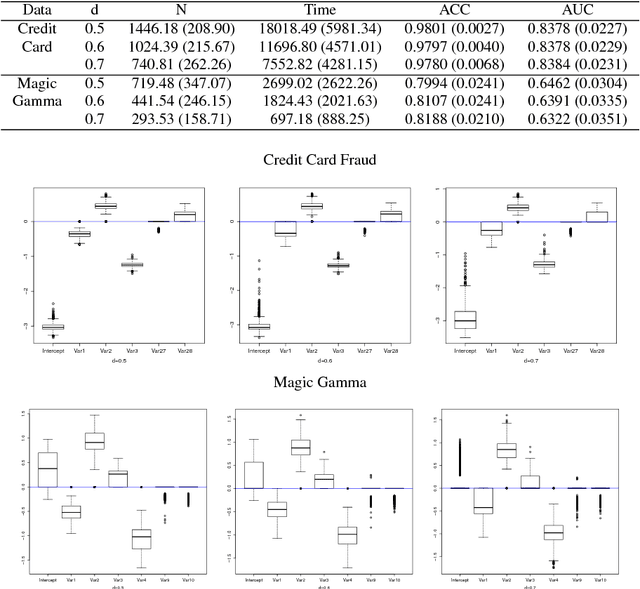
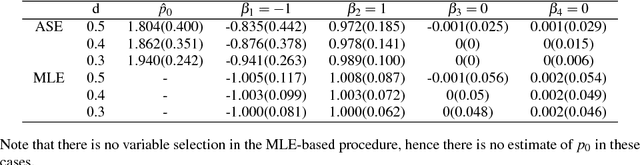
Modern computing and communication technologies can make data collection procedures very efficient. However, our ability to analyze large data sets and/or to extract information out from them is hard-pressed to keep up with our capacities for data collection. Among these huge data sets, some of them are not collected for any particular research purpose. For a classification problem, this means that the essential label information may not be readily obtainable, in the data set in hands, and an extra labeling procedure is required such that we can have enough label information to be used for constructing a classification model. When the size of a data set is huge, to label each subject in it will cost a lot in both capital and time. Thus, it is an important issue to decide which subjects should be labeled first in order to efficiently reduce the training cost/time. Active learning method is a promising outlet for this situation, because with the active learning ideas, we can select the unlabeled subjects sequentially without knowing their label information. In addition, there will be no confirmed information about the essential variables for constructing an efficient classification rule. Thus, how to merge a variable selection scheme with an active learning procedure is of interest. In this paper, we propose a procedure for building binary classification models when the complete label information is not available in the beginning of the training stage. We study an model-based active learning procedure with sequential variable selection schemes, and discuss the results of the proposed procedure from both theoretical and numerical aspects.
Distributed sequential method for analyzing massive data
Dec 22, 2018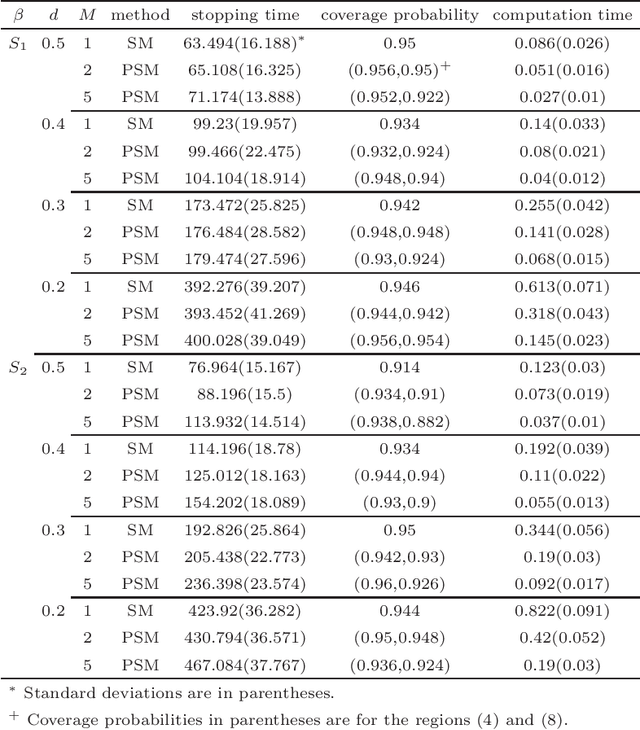
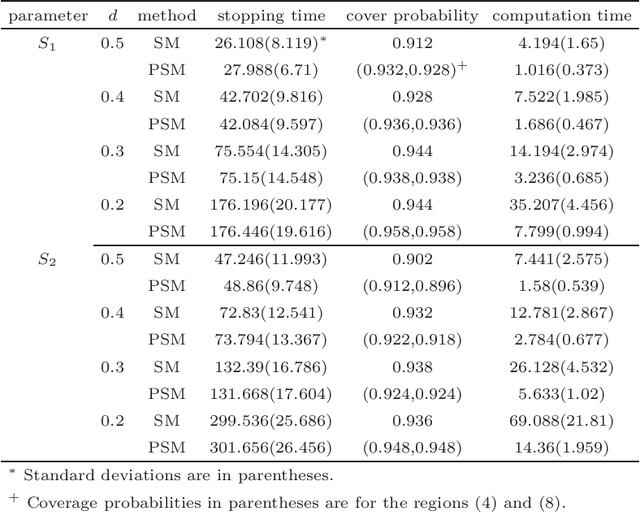
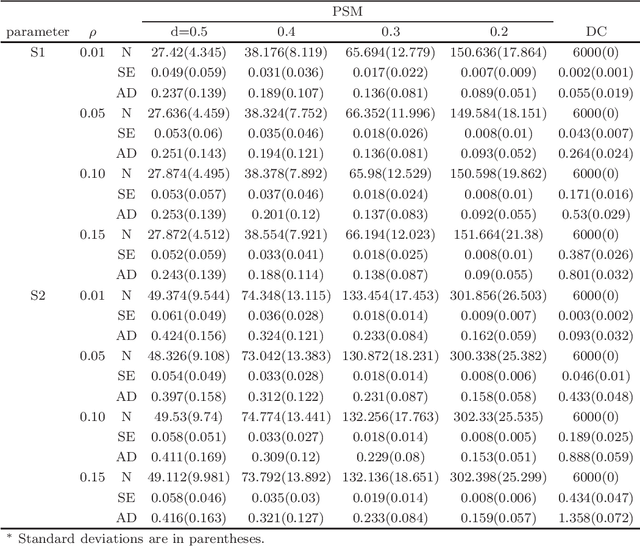
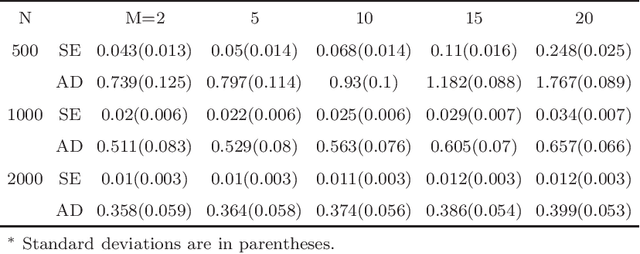
To analyse a very large data set containing lengthy variables, we adopt a sequential estimation idea and propose a parallel divide-and-conquer method. We conduct several conventional sequential estimation procedures separately, and properly integrate their results while maintaining the desired statistical properties. Additionally, using a criterion from the statistical experiment design, we adopt an adaptive sample selection, together with an adaptive shrinkage estimation method, to simultaneously accelerate the estimation procedure and identify the effective variables. We confirm the cogency of our methods through theoretical justifications and numerical results derived from synthesized data sets. We then apply the proposed method to three real data sets, including those pertaining to appliance energy use and particulate matter concentration.
Evaluating the diagnostic powers of variables and their linear combinations when the gold standard is continuous
May 09, 2011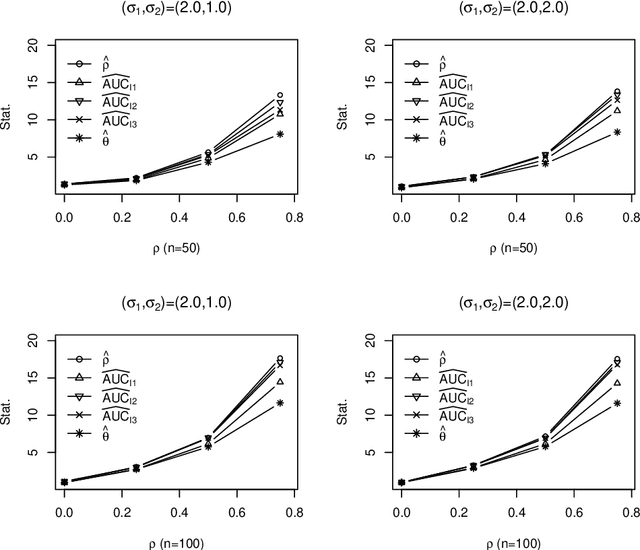
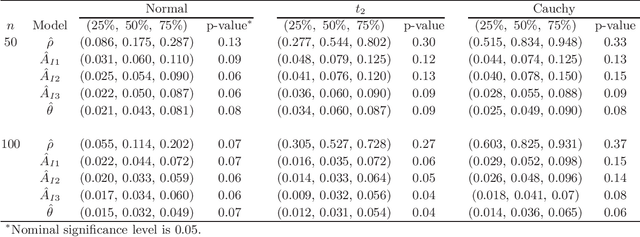
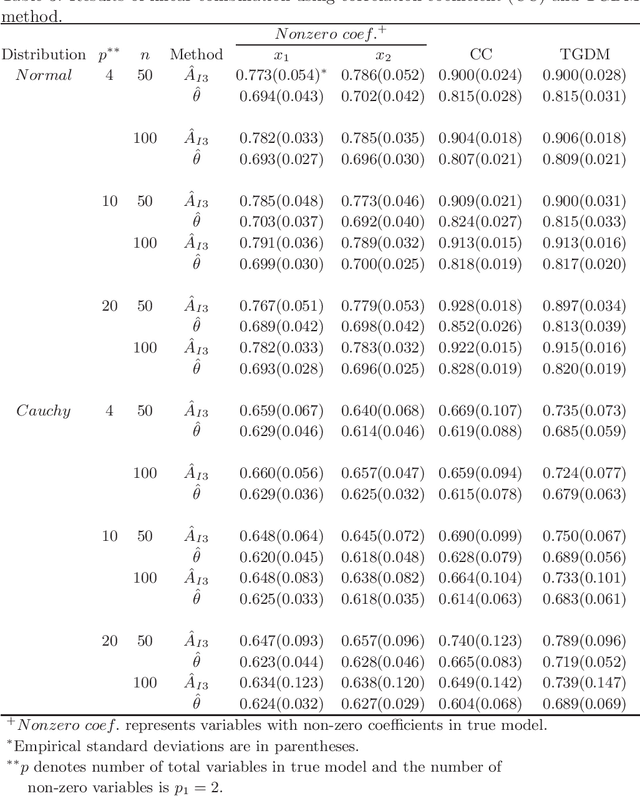
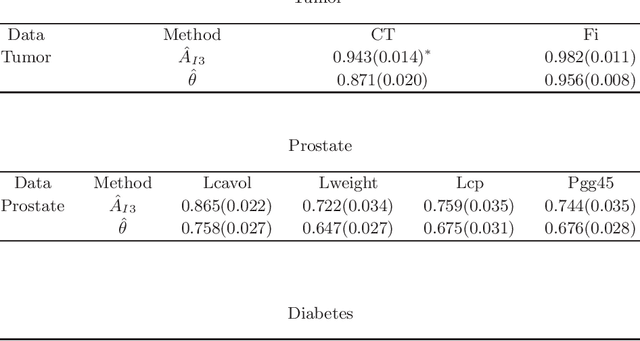
The receiver operating characteristic (ROC) curve is a very useful tool for analyzing the diagnostic/classification power of instruments/classification schemes as long as a binary-scale gold standard is available. When the gold standard is continuous and there is no confirmative threshold, ROC curve becomes less useful. Hence, there are several extensions proposed for evaluating the diagnostic potential of variables of interest. However, due to the computational difficulties of these nonparametric based extensions, they are not easy to be used for finding the optimal combination of variables to improve the individual diagnostic power. Therefore, we propose a new measure, which extends the AUC index for identifying variables with good potential to be used in a diagnostic scheme. In addition, we propose a threshold gradient descent based algorithm for finding the best linear combination of variables that maximizes this new measure, which is applicable even when the number of variables is huge. The estimate of the proposed index and its asymptotic property are studied. The performance of the proposed method is illustrated using both synthesized and real data sets.