 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning across label confidence distributions using Filtered Transfer Learning
Jun 03, 2020

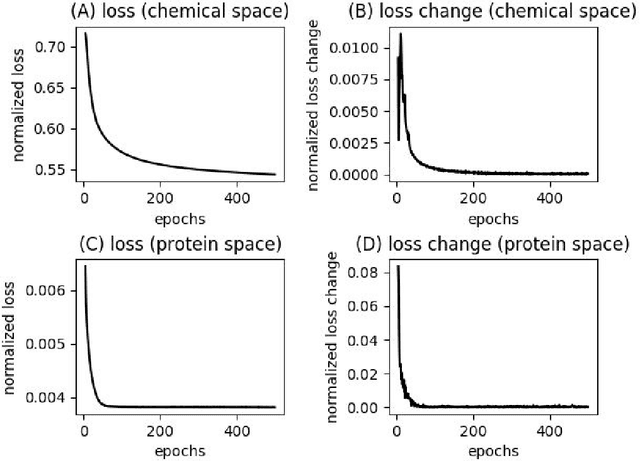

Performance of neural network models relies on the availability of large datasets with minimal levels of uncertainty. Transfer Learning (TL) models have been proposed to resolve the issue of small dataset size by letting the model train on a bigger, task-related reference dataset and then fine-tune on a smaller, task-specific dataset. In this work, we apply a transfer learning approach to improve predictive power in noisy data systems with large variable confidence datasets. We propose a deep neural network method called Filtered Transfer Learning (FTL) that defines multiple tiers of data confidence as separate tasks in a transfer learning setting. The deep neural network is fine-tuned in a hierarchical process by iteratively removing (filtering) data points with lower label confidence, and retraining. In this report we use FTL for predicting the interaction of drugs and proteins. We demonstrate that using FTL to learn stepwise, across the label confidence distribution, results in higher performance compared to deep neural network models trained on a single confidence range. We anticipate that this approach will enable the machine learning community to benefit from large datasets with uncertain labels in fields such as biology and medicine.
Predicting drug properties with parameter-free machine learning: Pareto-Optimal Embedded Modeling (POEM)
Feb 11, 2020
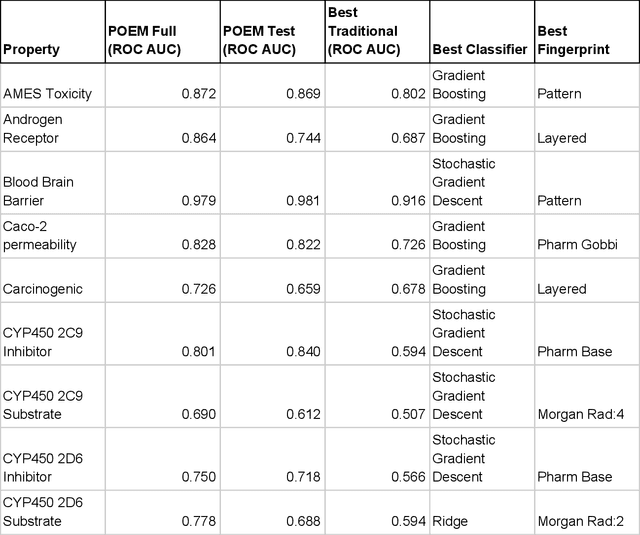


The prediction of absorption, distribution, metabolism, excretion, and toxicity (ADMET) of small molecules from their molecular structure is a central problem in medicinal chemistry with great practical importance in drug discovery. Creating predictive models conventionally requires substantial trial-and-error for the selection of molecular representations, machine learning (ML) algorithms, and hyperparameter tuning. A generally applicable method that performs well on all datasets without tuning would be of great value but is currently lacking. Here, we describe Pareto-Optimal Embedded Modeling (POEM), a similarity-based method for predicting molecular properties. POEM is a non-parametric, supervised ML algorithm developed to generate reliable predictive models without need for optimization. POEMs predictive strength is obtained by combining multiple different representations of molecular structures in a context-specific manner, while maintaining low dimensionality. We benchmark POEM relative to industry-standard ML algorithms and published results across 17 classifications tasks. POEM performs well in all cases and reduces the risk of overfitting.