 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrojanGYM: A Detector-in-the-Loop LLM for Adaptive RTL Hardware Trojan Insertion
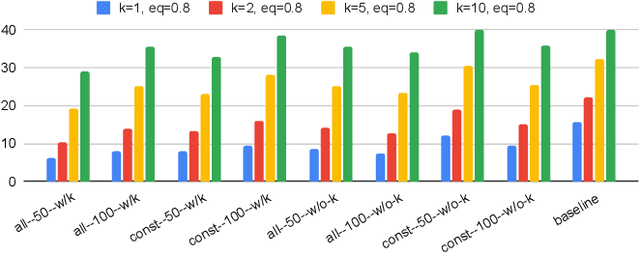
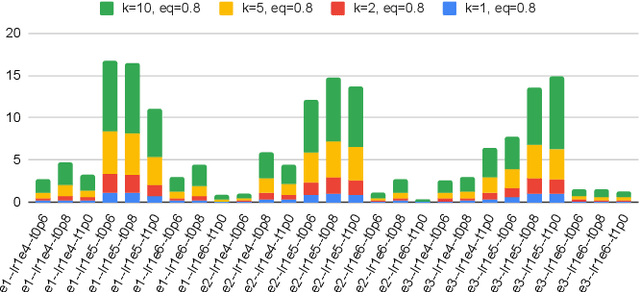
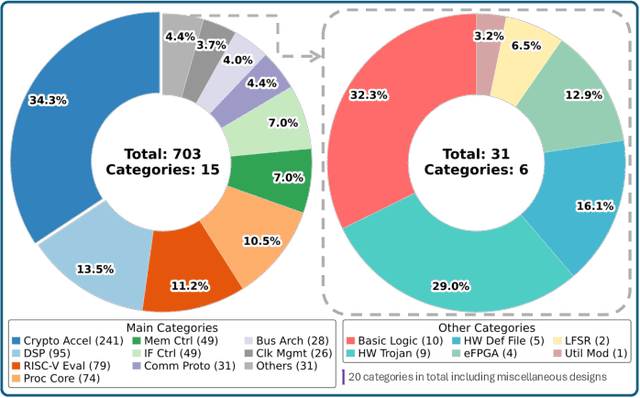
Jan 23, 2026Hardware Trojans (HTs) remain a critical threat because learning-based detectors often overfit to narrow trigger/payload patterns and small, stylized benchmarks. We introduce TrojanGYM, an agentic, LLM-driven framework that automatically curates HT insertions to expose detector blind spots while preserving design correctness. Given high-level HT specifications, a suite of cooperating LLM agents (instantiated with GPT-4, LLaMA-3.3-70B, and Gemini-2.5Pro) proposes and refines RTL modifications that realize diverse triggers and payloads without impacting normal functionality. TrojanGYM implements a feedback-driven benchmark generation loop co-designed with HT detectors, in which constraint-aware syntactic checking and GNN-based HT detectors provide feedback that iteratively refines HT specifications and insertion strategies to better surface detector blind spots. We further propose Robust-GNN4TJ, a new implementation of the GNN4TJ with improved graph extraction, training robustness, and prediction reliability, especially on LLM-generated HT designs. On the most challenging TrojanGYM-generated benchmarks, Robust-GNN4TJ raises HT detection rates from 0% to 60% relative to a prior GNN-based detector. We instantiate TrojanGYM on SRAM, AES-128, and UART designs at RTL level, and show that it systematically produces diverse, functionally correct HTs that reach up to 83.33% evasion rates against modern GNN-based detectors, revealing robustness gaps that are not apparent when these detectors are evaluated solely on existing TrustHub-style benchmarks. Post peer-review, we will release all codes and artifacts.
VeriContaminated: Assessing LLM-Driven Verilog Coding for Data Contamination
Mar 17, 2025Large Language Models (LLMs) have revolutionized code generation, achieving exceptional results on various established benchmarking frameworks. However, concerns about data contamination - where benchmark data inadvertently leaks into pre-training or fine-tuning datasets - raise questions about the validity of these evaluations. While this issue is known, limiting the industrial adoption of LLM-driven software engineering, hardware coding has received little to no attention regarding these risks. For the first time, we analyze state-of-the-art (SOTA) evaluation frameworks for Verilog code generation (VerilogEval and RTLLM), using established methods for contamination detection (CCD and Min-K% Prob). We cover SOTA commercial and open-source LLMs (CodeGen2.5, Minitron 4b, Mistral 7b, phi-4 mini, LLaMA-{1,2,3.1}, GPT-{2,3.5,4o}, Deepseek-Coder, and CodeQwen 1.5), in baseline and fine-tuned models (RTLCoder and Verigen). Our study confirms that data contamination is a critical concern. We explore mitigations and the resulting trade-offs for code quality vs fairness (i.e., reducing contamination toward unbiased benchmarking).
VeriLeaky: Navigating IP Protection vs Utility in Fine-Tuning for LLM-Driven Verilog Coding
Mar 17, 2025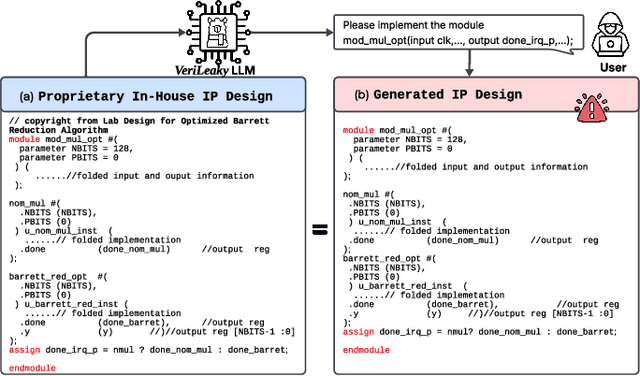
Large language models (LLMs) offer significant potential for coding, yet fine-tuning (FT) with curated data is essential for niche languages like Verilog. Using proprietary intellectual property (IP) for FT presents a serious risk, as FT data can be leaked through LLM inference. This leads to a critical dilemma for design houses: seeking to build externally accessible LLMs offering competitive Verilog coding, how can they leverage in-house IP to enhance FT utility while ensuring IP protection? For the first time in the literature, we study this dilemma. Using LLaMA 3.1-8B, we conduct in-house FT on a baseline Verilog dataset (RTLCoder) supplemented with our own in-house IP, which is validated through multiple tape-outs. To rigorously assess IP leakage, we quantify structural similarity (AST/Dolos) and functional equivalence (Synopsys Formality) between generated codes and our in-house IP. We show that our IP can indeed be leaked, confirming the threat. As defense, we evaluate logic locking of Verilog codes (ASSURE). This offers some level of protection, yet reduces the IP's utility for FT and degrades the LLM's performance. Our study shows the need for novel strategies that are both effective and minimally disruptive to FT, an essential effort for enabling design houses to fully utilize their proprietary IP toward LLM-driven Verilog coding.
LLMs and the Future of Chip Design: Unveiling Security Risks and Building Trust
May 11, 2024Chip design is about to be revolutionized by the integration of large language, multimodal, and circuit models (collectively LxMs). While exploring this exciting frontier with tremendous potential, the community must also carefully consider the related security risks and the need for building trust into using LxMs for chip design. First, we review the recent surge of using LxMs for chip design in general. We cover state-of-the-art works for the automation of hardware description language code generation and for scripting and guidance of essential but cumbersome tasks for electronic design automation tools, e.g., design-space exploration, tuning, or designer training. Second, we raise and provide initial answers to novel research questions on critical issues for security and trustworthiness of LxM-powered chip design from both the attack and defense perspectives.