 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCNN-based automatic segmentation of Lumen & Media boundaries in IVUS images using closed polygonal chains
Sep 29, 2023We propose an automatic segmentation method for lumen and media with irregular contours in IntraVascular ultra-sound (IVUS) images. In contrast to most approaches that broadly label each pixel as either lumen, media, or background, we propose to approximate the lumen and media contours by closed polygonal chains. The chain vertices are placed at fixed angles obtained by dividing the entire 360\degree~angular space into equally spaced angles, and we predict their radius using an adaptive-subband-decomposition CNN. We consider two loss functions during training. The first is a novel loss function using the Jaccard Measure (JM) to quantify the similarities between the predicted lumen and media segments and the corresponding ground-truth image segments. The second loss function is the traditional Mean Squared Error. The proposed architecture significantly reduces computational costs by replacing the popular auto-encoder structure with a simple CNN as the encoder and the decoder is reduced to simply joining the consecutive predicted points. We evaluated our network on the publicly available IVUS-Challenge-2011 dataset using two performance metrics, namely JM and Hausdorff Distance (HD). The evaluation results show that our proposed network mostly outperforms the state-of-the-art lumen and media segmentation methods.
A Structurally Regularized CNN Architecture via Adaptive Subband Decomposition
Jun 29, 2023



We propose a generalized convolutional neural network (CNN) architecture that first decomposes the input signal into subbands by an adaptive filter bank structure, and then uses convolutional layers to extract features from each subband independently. Fully connected layers finally combine the extracted features to perform classification. The proposed architecture restrains each of the subband CNNs from learning using the entire input signal spectrum, resulting in structural regularization. Our proposed CNN architecture is fully compatible with the end-to-end learning mechanism of typical CNN architectures and learns the subband decomposition from the input dataset. We show that the proposed CNN architecture has attractive properties, such as robustness to input and weight-and-bias quantization noise, compared to regular full-band CNN architectures. Importantly, the proposed architecture significantly reduces computational costs, while maintaining state-of-the-art classification accuracy. Experiments on image classification tasks using the MNIST, CIFAR-10/100, Caltech-101, and ImageNet-2012 datasets show that the proposed architecture allows accuracy surpassing state-of-the-art results. On the ImageNet-2012 dataset, we achieved top-5 and top-1 validation set accuracy of 86.91% and 69.73%, respectively. Notably, the proposed architecture offers over 90% reduction in computation cost in the inference path and approximately 75% reduction in back-propagation (per iteration) with just a single-layer subband decomposition. With a 2-layer subband decomposition, the computational gains are even more significant with comparable accuracy results to the single-layer decomposition.
A Structurally Regularized Convolutional Neural Network for Image Classification using Wavelet-based SubBand Decomposition
Mar 02, 2021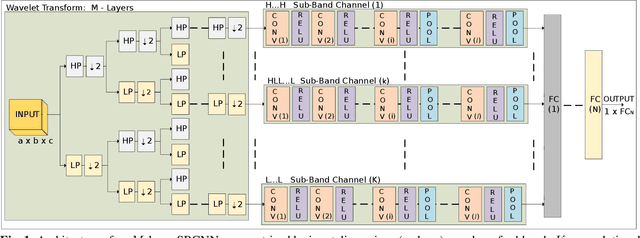
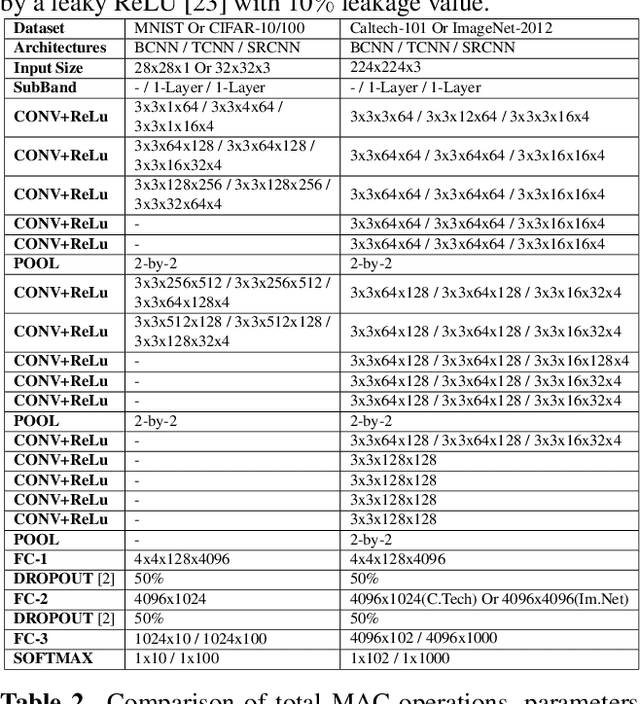
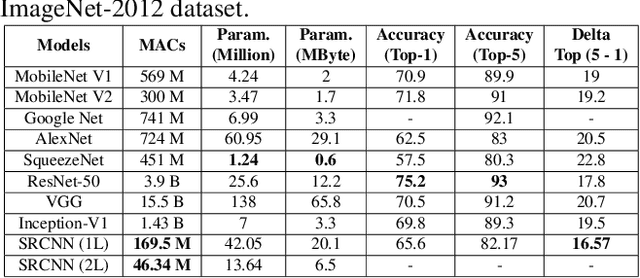
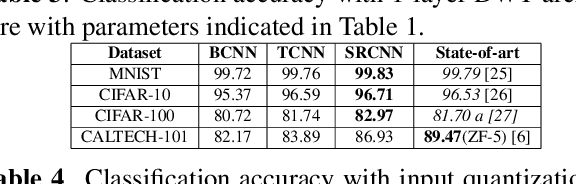
We propose a convolutional neural network (CNN) architecture for image classification based on subband decomposition of the image using wavelets. The proposed architecture decomposes the input image spectra into multiple critically sampled subbands, extracts features using a single CNN per subband, and finally, performs classification by combining the extracted features using a fully connected layer. Processing each of the subbands by an individual CNN, thereby limiting the learning scope of each CNN to a single subband, imposes a form of structural regularization. This provides better generalization capability as seen by the presented results. The proposed architecture achieves best-in-class performance in terms of total multiply-add-accumulator operations and nearly best-in-class performance in terms of total parameters required, yet it maintains competitive classification performance. We also show the proposed architecture is more robust than the regular full-band CNN to noise caused by weight-and-bias quantization and input quantization.
FoodTracker: A Real-time Food Detection Mobile Application by Deep Convolutional Neural Networks
Sep 16, 2019



We present a mobile application made to recognize food items of multi-object meal from a single image in real-time, and then return the nutrition facts with components and approximate amounts. Our work is organized in two parts. First, we build a deep convolutional neural network merging with YOLO, a state-of-the-art detection strategy, to achieve simultaneous multi-object recognition and localization with nearly 80% mean average precision. Second, we adapt our model into a mobile application with extending function for nutrition analysis. After inferring and decoding the model output in the app side, we present detection results that include bounding box position and class label in either real-time or local mode. Our model is well-suited for mobile devices with negligible inference time and small memory requirements with a deep learning algorithm.