 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable Deepfake Video Detection using Convolutional Neural Network and CapsuleNet
Apr 19, 2024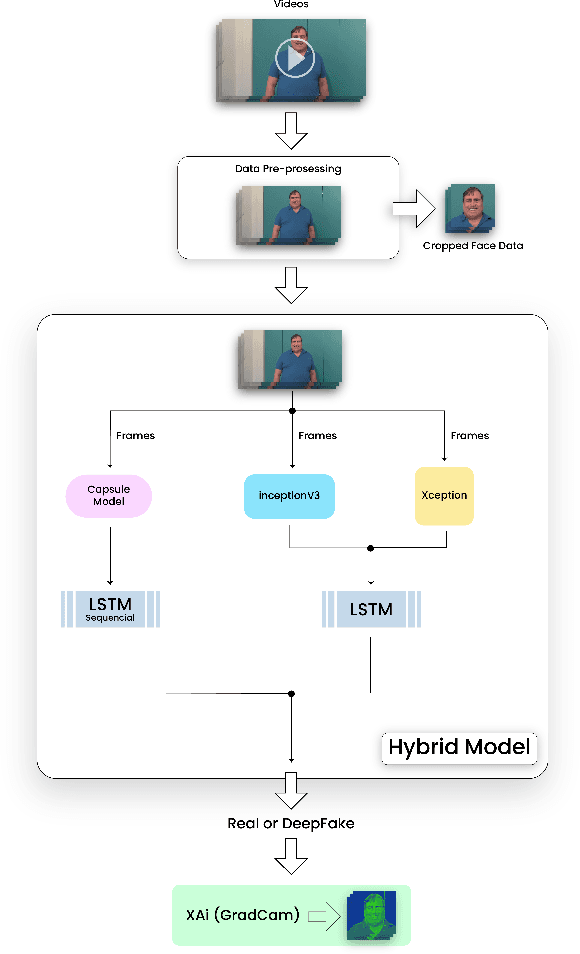


Deepfake technology, derived from deep learning, seamlessly inserts individuals into digital media, irrespective of their actual participation. Its foundation lies in machine learning and Artificial Intelligence (AI). Initially, deepfakes served research, industry, and entertainment. While the concept has existed for decades, recent advancements render deepfakes nearly indistinguishable from reality. Accessibility has soared, empowering even novices to create convincing deepfakes. However, this accessibility raises security concerns.The primary deepfake creation algorithm, GAN (Generative Adversarial Network), employs machine learning to craft realistic images or videos. Our objective is to utilize CNN (Convolutional Neural Network) and CapsuleNet with LSTM to differentiate between deepfake-generated frames and originals. Furthermore, we aim to elucidate our model's decision-making process through Explainable AI, fostering transparent human-AI relationships and offering practical examples for real-life scenarios.
Cyberbullying Detection Using Deep Neural Network from Social Media Comments in Bangla Language
Jun 08, 2021



Cyberbullying or Online harassment detection on social media for various major languages is currently being given a good amount of focus by researchers worldwide. Being the seventh most speaking language in the world and increasing usage of online platform among the Bengali speaking people urge to find effective detection technique to handle the online harassment. In this paper, we have proposed binary and multiclass classification model using hybrid neural network for bully expression detection in Bengali language. We have used 44,001 users comments from popular public Facebook pages, which fall into five classes - Non-bully, Sexual, Threat, Troll and Religious. We have examined the performance of our proposed models from different perspective. Our binary classification model gives 87.91% accuracy, whereas introducing ensemble technique after neural network for multiclass classification, we got 85% accuracy.
Bangla Text Dataset and Exploratory Analysis for Online Harassment Detection
Feb 04, 2021



Being the seventh most spoken language in the world, the use of the Bangla language online has increased in recent times. Hence, it has become very important to analyze Bangla text data to maintain a safe and harassment-free online place. The data that has been made accessible in this article has been gathered and marked from the comments of people in public posts by celebrities, government officials, athletes on Facebook. The total amount of collected comments is 44001. The dataset is compiled with the aim of developing the ability of machines to differentiate whether a comment is a bully expression or not with the help of Natural Language Processing and to what extent it is improper if it is an inappropriate comment. The comments are labeled with different categories of harassment. Exploratory analysis from different perspectives is also included in this paper to have a detailed overview. Due to the scarcity of data collection of categorized Bengali language comments, this dataset can have a significant role for research in detecting bully words, identifying inappropriate comments, detecting different categories of Bengali bullies, etc. The dataset is publicly available at https://data.mendeley.com/datasets/9xjx8twk8p.