 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable Deepfake Video Detection using Convolutional Neural Network and CapsuleNet
Apr 19, 2024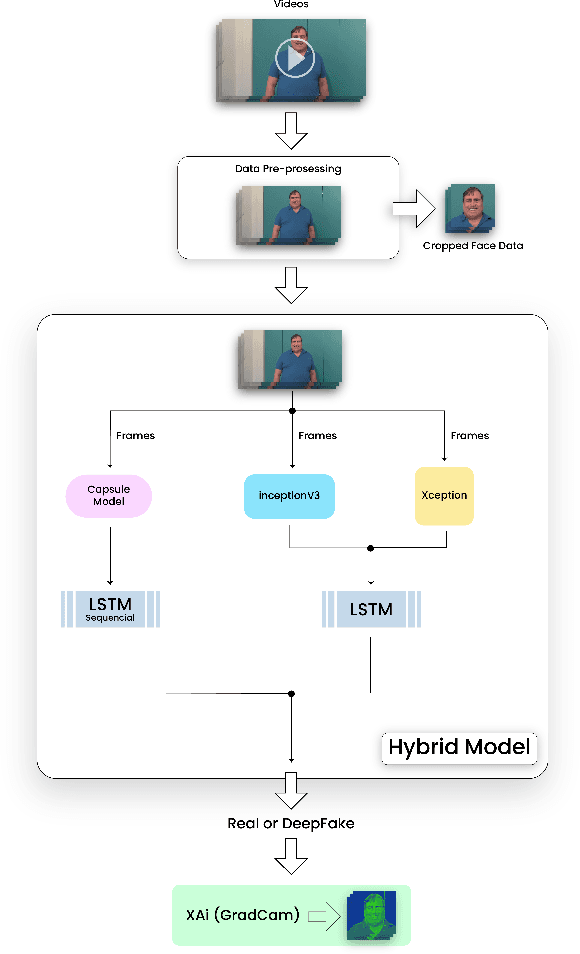


Deepfake technology, derived from deep learning, seamlessly inserts individuals into digital media, irrespective of their actual participation. Its foundation lies in machine learning and Artificial Intelligence (AI). Initially, deepfakes served research, industry, and entertainment. While the concept has existed for decades, recent advancements render deepfakes nearly indistinguishable from reality. Accessibility has soared, empowering even novices to create convincing deepfakes. However, this accessibility raises security concerns.The primary deepfake creation algorithm, GAN (Generative Adversarial Network), employs machine learning to craft realistic images or videos. Our objective is to utilize CNN (Convolutional Neural Network) and CapsuleNet with LSTM to differentiate between deepfake-generated frames and originals. Furthermore, we aim to elucidate our model's decision-making process through Explainable AI, fostering transparent human-AI relationships and offering practical examples for real-life scenarios.
Analysis of Real-Time Hostile Activitiy Detection from Spatiotemporal Features Using Time Distributed Deep CNNs, RNNs and Attention-Based Mechanisms
Feb 21, 2023

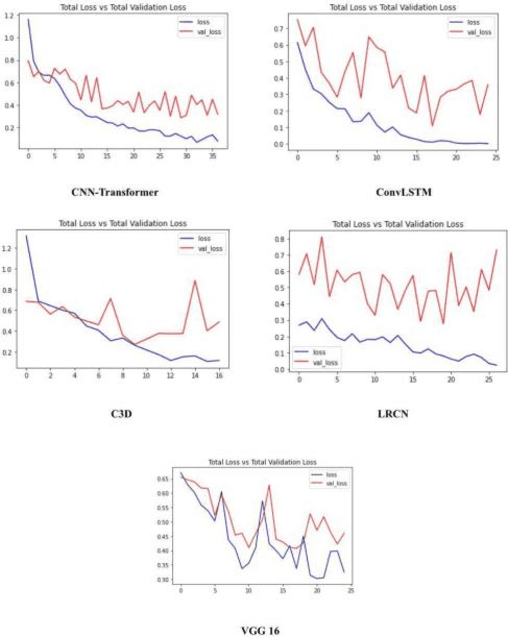

Real-time video surveillance, through CCTV camera systems has become essential for ensuring public safety which is a priority today. Although CCTV cameras help a lot in increasing security, these systems require constant human interaction and monitoring. To eradicate this issue, intelligent surveillance systems can be built using deep learning video classification techniques that can help us automate surveillance systems to detect violence as it happens. In this research, we explore deep learning video classification techniques to detect violence as they are happening. Traditional image classification techniques fall short when it comes to classifying videos as they attempt to classify each frame separately for which the predictions start to flicker. Therefore, many researchers are coming up with video classification techniques that consider spatiotemporal features while classifying. However, deploying these deep learning models with methods such as skeleton points obtained through pose estimation and optical flow obtained through depth sensors, are not always practical in an IoT environment. Although these techniques ensure a higher accuracy score, they are computationally heavier. Keeping these constraints in mind, we experimented with various video classification and action recognition techniques such as ConvLSTM, LRCN (with both custom CNN layers and VGG-16 as feature extractor) CNNTransformer and C3D. We achieved a test accuracy of 80% on ConvLSTM, 83.33% on CNN-BiLSTM, 70% on VGG16-BiLstm ,76.76% on CNN-Transformer and 80% on C3D.