 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTracking the Takes and Trajectories of English-Language News Narratives across Trustworthy and Worrisome Websites
Jan 15, 2025



Understanding how misleading and outright false information enters news ecosystems remains a difficult challenge that requires tracking how narratives spread across thousands of fringe and mainstream news websites. To do this, we introduce a system that utilizes encoder-based large language models and zero-shot stance detection to scalably identify and track news narratives and their attitudes across over 4,000 factually unreliable, mixed-reliability, and factually reliable English-language news websites. Running our system over an 18 month period, we track the spread of 146K news stories. Using network-based interference via the NETINF algorithm, we show that the paths of news narratives and the stances of websites toward particular entities can be used to uncover slanted propaganda networks (e.g., anti-vaccine and anti-Ukraine) and to identify the most influential websites in spreading these attitudes in the broader news ecosystem. We hope that increased visibility into our distributed news ecosystem can help with the reporting and fact-checking of propaganda and disinformation.
TATA: Stance Detection via Topic-Agnostic and Topic-Aware Embeddings
Oct 22, 2023



Stance detection is important for understanding different attitudes and beliefs on the Internet. However, given that a passage's stance toward a given topic is often highly dependent on that topic, building a stance detection model that generalizes to unseen topics is difficult. In this work, we propose using contrastive learning as well as an unlabeled dataset of news articles that cover a variety of different topics to train topic-agnostic/TAG and topic-aware/TAW embeddings for use in downstream stance detection. Combining these embeddings in our full TATA model, we achieve state-of-the-art performance across several public stance detection datasets (0.771 $F_1$-score on the Zero-shot VAST dataset). We release our code and data at https://github.com/hanshanley/tata.
Watch Your Language: Large Language Models and Content Moderation
Sep 25, 2023
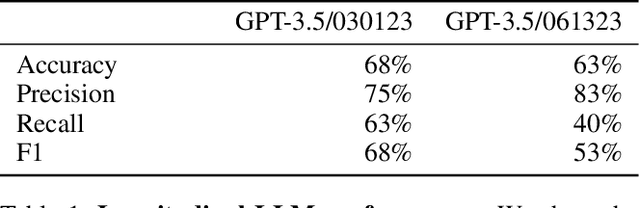

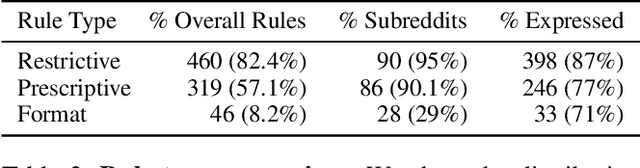
Large language models (LLMs) have exploded in popularity due to their ability to perform a wide array of natural language tasks. Text-based content moderation is one LLM use case that has received recent enthusiasm, however, there is little research investigating how LLMs perform in content moderation settings. In this work, we evaluate a suite of modern, commercial LLMs (GPT-3, GPT-3.5, GPT-4) on two common content moderation tasks: rule-based community moderation and toxic content detection. For rule-based community moderation, we construct 95 LLM moderation-engines prompted with rules from 95 Reddit subcommunities and find that LLMs can be effective at rule-based moderation for many communities, achieving a median accuracy of 64% and a median precision of 83%. For toxicity detection, we find that LLMs significantly outperform existing commercially available toxicity classifiers. However, we also find that recent increases in model size add only marginal benefit to toxicity detection, suggesting a potential performance plateau for LLMs on toxicity detection tasks. We conclude by outlining avenues for future work in studying LLMs and content moderation.
Specious Sites: Tracking the Spread and Sway of Spurious News Stories at Scale
Aug 03, 2023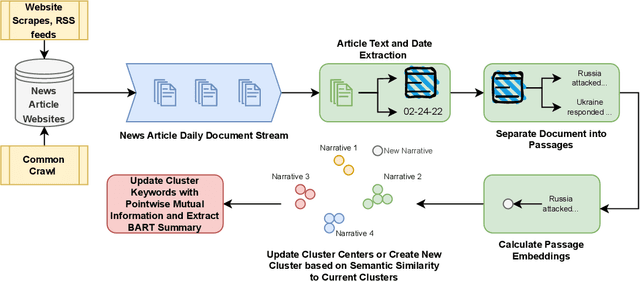

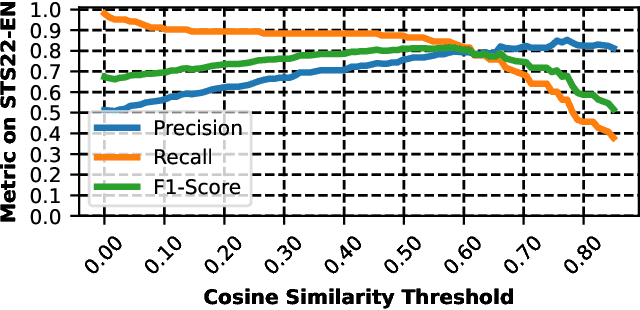

Misinformation, propaganda, and outright lies proliferate on the web, with some narratives having dangerous real-world consequences on public health, elections, and individual safety. However, despite the impact of misinformation, the research community largely lacks automated and programmatic approaches for tracking news narratives across online platforms. In this work, utilizing daily scrapes of 1,404 unreliable news websites, the large-language model MPNet, and DP-Means clustering, we introduce a system to automatically isolate and analyze the narratives spread within online ecosystems. Identifying 55,301 narratives on these 1,404 websites, we describe the most prevalent narratives spread in 2022 and identify the most influential websites that originate and magnify narratives. Finally, we show how our system can be utilized to detect new narratives originating from unreliable news websites and aid fact-checkers like Politifact, Reuters, and AP News in more quickly addressing misinformation stories.
Machine-Made Media: Monitoring the Mobilization of Machine-Generated Articles on Misinformation and Mainstream News Websites
May 16, 2023With the increasing popularity of generative large language models (LLMs) like ChatGPT, an increasing number of news websites have begun utilizing them to generate articles. However, not only can these language models produce factually inaccurate articles on reputable websites but disreputable news sites can utilize these LLMs to mass produce misinformation. To begin to understand this phenomenon, we present one of the first large-scale studies of the prevalence of synthetic articles within online news media. To do this, we train a DeBERTa-based synthetic news detector and classify over 12.91 million articles from 3,074 misinformation and mainstream news websites. We find that between January 1, 2022 and April 1, 2023, the relative number of synthetic news articles increased by 79.4% on mainstream websites while increasing by 342% on misinformation sites. Analyzing the impact of the release of ChatGPT using an interrupted-time-series, we show that while its release resulted in a marked increase in synthetic articles on small sites as well as misinformation news websites, there was not a corresponding increase on large mainstream news websites. Finally, using data from the social media platform Reddit, we find that social media users interacted more with synthetic articles in March 2023 relative to January 2022.
Predicting IPv4 Services Across All Ports
Mar 02, 2023



Internet-wide scanning is commonly used to understand the topology and security of the Internet. However, IPv4 Internet scans have been limited to scanning only a subset of services -- exhaustively scanning all IPv4 services is too costly and no existing bandwidth-saving frameworks are designed to scan IPv4 addresses across all ports. In this work we introduce GPS, a system that efficiently discovers Internet services across all ports. GPS runs a predictive framework that learns from extremely small sample sizes and is highly parallelizable, allowing it to quickly find patterns between services across all 65K ports and a myriad of features. GPS computes service predictions in 13 minutes (four orders of magnitude faster than prior work) and finds 92.5% of services across all ports with 131x less bandwidth, and 204x more precision, compared to exhaustive scanning. GPS is the first work to show that, given at least two responsive IP addresses on a port to train from, predicting the majority of services across all ports is possible and practical.
Partial Mobilization: Tracking Multilingual Information Flows Amongst Russian Media Outlets and Telegram
Jan 25, 2023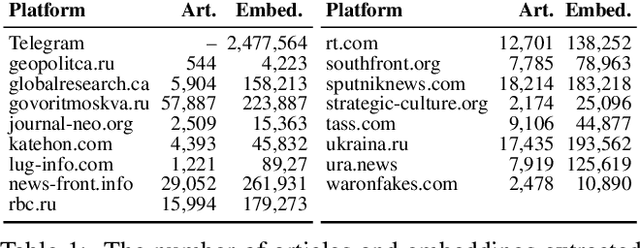
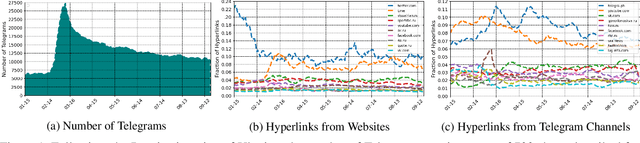
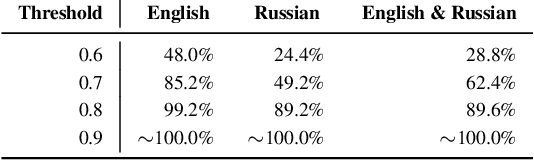
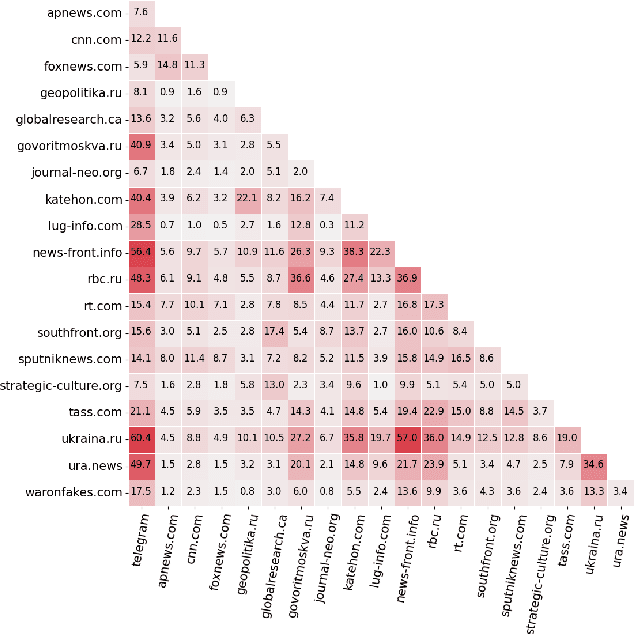
In response to disinformation and propaganda from Russian online media following the Russian invasion of Ukraine, Russian outlets including Russia Today and Sputnik News were banned throughout Europe. Many of these Russian outlets, in order to reach their audiences, began to heavily promote their content on messaging services like Telegram. In this work, to understand this phenomenon, we study how 16 Russian media outlets have interacted with and utilized 732 Telegram channels throughout 2022. To do this, we utilize a multilingual version of the foundational model MPNet to embed articles and Telegram messages in a shared embedding space and semantically compare content. Leveraging a parallelized version of DP-Means clustering, we perform paragraph-level topic/narrative extraction and time-series analysis with Hawkes Processes. With this approach, across our websites, we find between 2.3% (ura.news) and 26.7% (ukraina.ru) of their content originated/resulted from activity on Telegram. Finally, tracking the spread of individual narratives, we measure the rate at which these websites and channels disseminate content within the Russian media ecosystem.
Happenstance: Utilizing Semantic Search to Track Russian State Media Narratives about the Russo-Ukrainian War On Reddit
May 28, 2022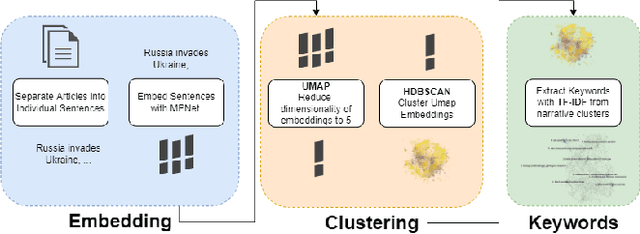
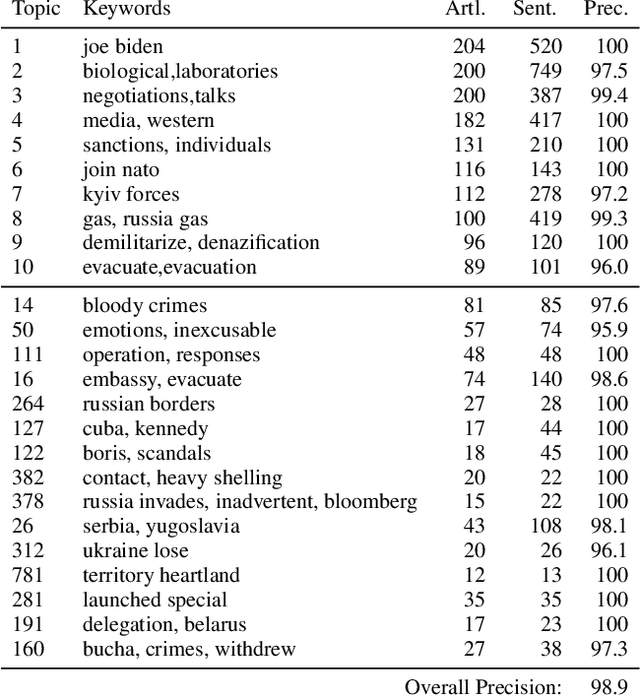
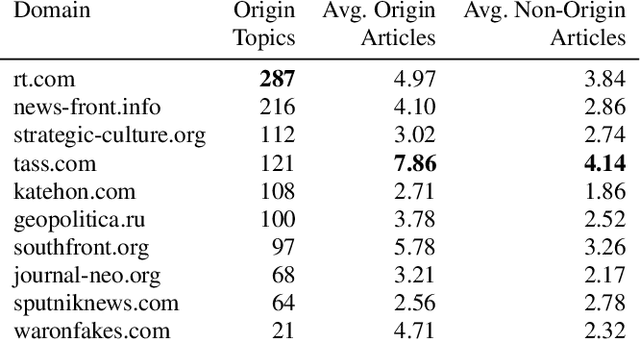
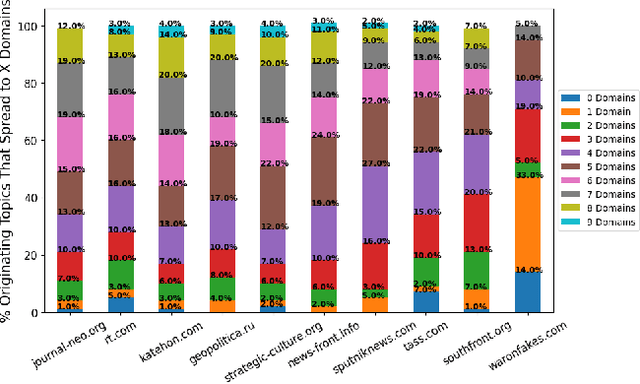
In the buildup to and in the weeks following the Russian Federation's invasion of Ukraine, Russian disinformation outlets output torrents of misleading and outright false information. In this work, we study the coordinated information campaign to understand the most prominent disinformation narratives touted by the Russian government to English-speaking audiences. To do this, we first perform sentence-level topic analysis using the large-language model MPNet on articles published by nine different Russian disinformation websites and the new Russian "fact-checking" website waronfakes.com. We show that smaller websites like katehon.com were highly effective at producing topics that were later echoed by other disinformation sites. After analyzing the set of Russian information narratives, we analyze their correspondence with narratives and topics of discussion on the r/Russia and 10 other political subreddits. Using MPNet and a semantic search algorithm, we map these subreddits' comments to the set of topics extracted from our set of disinformation websites, finding that 39.6% of r/Russia comments corresponded to narratives from Russian disinformation websites, compared to 8.86% on r/politics.