 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWatch Your Language: Large Language Models and Content Moderation
Paper and Code
Sep 25, 2023
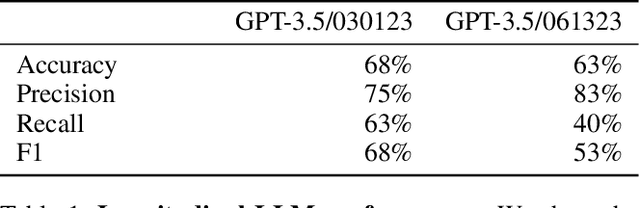

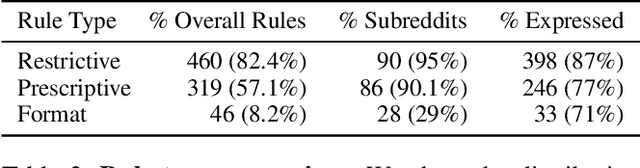
Large language models (LLMs) have exploded in popularity due to their ability to perform a wide array of natural language tasks. Text-based content moderation is one LLM use case that has received recent enthusiasm, however, there is little research investigating how LLMs perform in content moderation settings. In this work, we evaluate a suite of modern, commercial LLMs (GPT-3, GPT-3.5, GPT-4) on two common content moderation tasks: rule-based community moderation and toxic content detection. For rule-based community moderation, we construct 95 LLM moderation-engines prompted with rules from 95 Reddit subcommunities and find that LLMs can be effective at rule-based moderation for many communities, achieving a median accuracy of 64% and a median precision of 83%. For toxicity detection, we find that LLMs significantly outperform existing commercially available toxicity classifiers. However, we also find that recent increases in model size add only marginal benefit to toxicity detection, suggesting a potential performance plateau for LLMs on toxicity detection tasks. We conclude by outlining avenues for future work in studying LLMs and content moderation.