 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross Attention-guided Dense Network for Images Fusion
Sep 23, 2021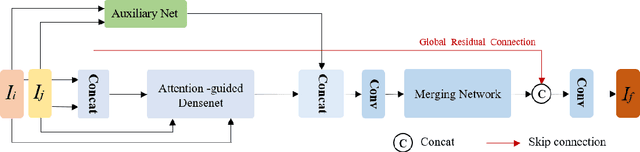
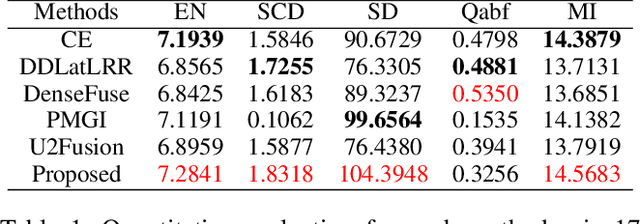
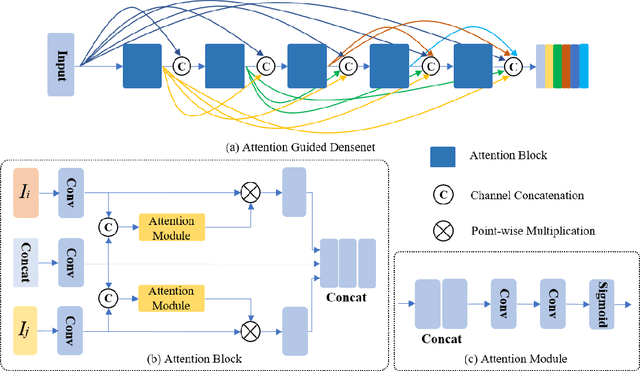
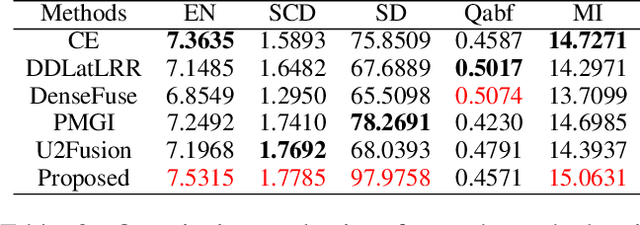
In recent years, various applications in computer vision have achieved substantial progress based on deep learning, which has been widely used for image fusion and shown to achieve adequate performance. However, suffering from limited ability in modelling the spatial correspondence of different source images, it still remains a great challenge for existing unsupervised image fusion models to extract appropriate feature and achieves adaptive and balanced fusion. In this paper, we propose a novel cross attention-guided image fusion network, which is a unified and unsupervised framework for multi-modal image fusion, multi-exposure image fusion, and multi-focus image fusion. Different from the existing self-attention module, our cross attention module focus on modelling the cross-correlation between different source images. Using the proposed cross attention module as core block, a densely connected cross attention-guided network is built to dynamically learn the spatial correspondence to derive better alignment of important details from different input images. Meanwhile, an auxiliary branch is also designed to model the long-range information, and a merging network is attached to finally reconstruct the fusion image. Extensive experiments have been carried out on publicly available datasets, and the results demonstrate that the proposed model outperforms the state-of-the-art quantitatively and qualitatively.